Getting started with anomaly detection
Anomaly detection is one of the most interesting applications in machine learning. While anomaly detection can be done in a both supervised and unsupervised manner, in most cases, it is done through unsupervised algorithms.
One of the best ways to get started with anomaly detection in Python is the pyod library. The authors decsribe PyOD as follow
PyOD includes more than 30 detection algorithms, from classical LOF (SIGMOD 2000) to the latest COPOD (ICDM 2020). Since 2017, PyOD [AZNL19] has been successfully used in numerous academic researches and commercial products [AGSW19,ALCJ+19,AWDL+19,AZNHL19]. It is also well acknowledged by the machine learning community with various dedicated posts/tutorials, including Analytics Vidhya, Towards Data Science, KDnuggets, Computer Vision News, and awesome-machine-learning.
So, it is clear that pyod is a good way to get started with anomaly detection!
The PyOD library
The PyOD library follows the same syntax as scikit-learn. Let’s say that you want to create a COPOD detector. COPOD is an advanced anomaly detection algorithm which stands for Copula-Based Outlier Detection. You can find the original paper here. You can do so in the following way:
# train the COPOD detector from pyod.models.copod import COPOD clf = COPOD() clf.fit(X_train) # get outlier scores y_train_scores = clf.decision_scores_ # raw outlier scores y_test_scores = clf.decision_function(X_test) # outlier scores
As you can see this is the same principle as if you were creating a classifier in scikit-learn. As you notice, the model can return a raw outlier score, but also a decision outcome.
A challenge with anomaly detection algorithms, is that they are producing scores, which you then have to interpret. Determning what is an anomaly and what is not an anomaly, can often depend on the context. SO, it is quite likely you will need to use the raw decision score, and then adapt it to your domain.
There are many different outlier detection methods in PyOd, and choosing the right one requires lots of tuning an experimentation. The authors of PyOD have created a very nice graphic comparing how different algorithms would react to the same problem.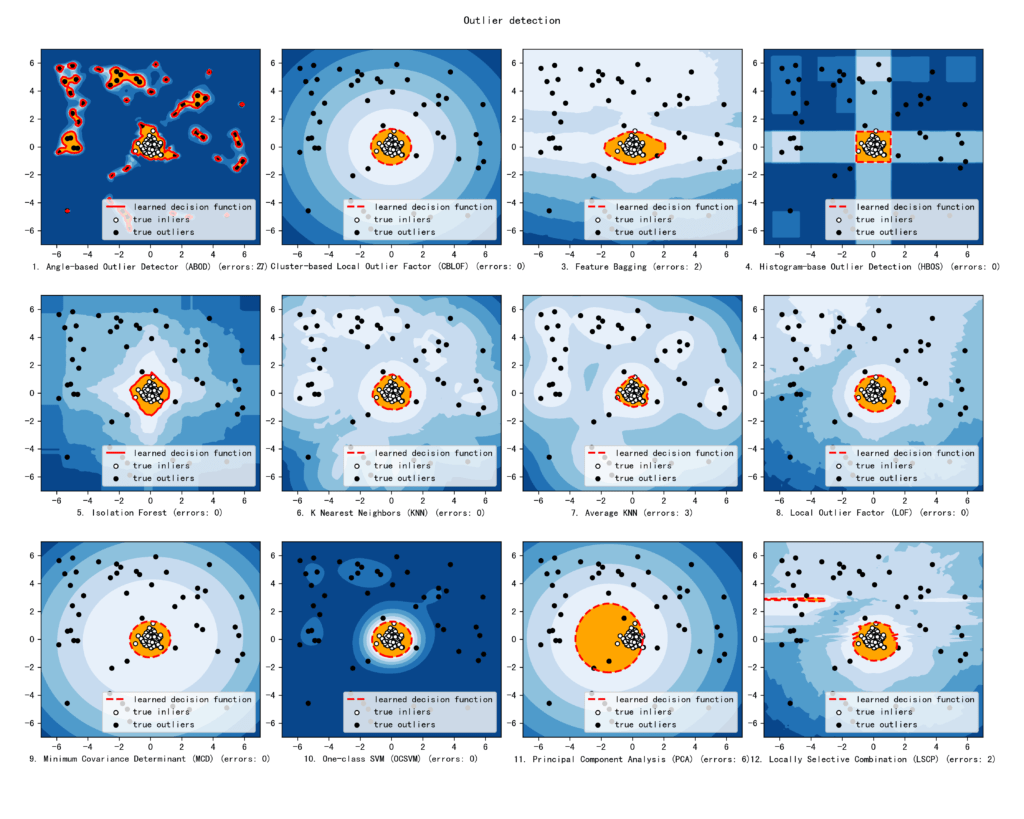
Anomaly detection
Anomaly/outlier detection is a popular subdomain of machine learning with many applications in domains like cybersecurity and fraud detection. In this short post we briefly talked about the PyOD library which is probably the best way to get started with anomaly detection in Python. If you are interested in learning more about the subject, also please make sure to check out the video below:
Do you want to become data scientist?

Do you want to become a data scientist and pursue a lucrative career with a high salary, working from anywhere in the world? I have developed a unique course based on my 10+ years of teaching experience in this area. The course offers the following:
- Learn all the basics of data science (value $10k+)
- Get premium mentoring (value at $1k/hour)
- We apply to jobs for you and we help you land a job, by preparing you for interviews (value at $50k+ per year)
- We provide a satisfaction guarantee!
If you want to learn more book a call with my team now or get in touch.