
Human-level concept learning
I am a huge fan of Joshua Tenenbaum and his research. Recently, he published in collaboration with Brenden Lake and Ruslan Salakhutdinov a new piece of research regarding “Bayesian Program Learning“.

The paper is actually entitled “Human-level concept learning through probabilistic program induction”. Bayesian program learning is an answer to one-shot learning. The idea behind one-shot learning is that humans can learn some concepts even after a single example. For example, a baby needs to watch an object to fall from a table only once in order to understand there is a force called “gravity” pulling objects down. Similarly, if someone is shown a single example from two distinct alphabets (let’s say Chinese and English) it would be easy to classify subsequent examples from the two alphabets as belonging to one or the other. There is also evidence to suggest that there is a special mechanism in the brain activated just for one-shot learning.
This is particularly interesting, since machine learning algorithms have problem understanding how to generalise from a small piece of information. While machine learning has been very successful in a wide range of problems, the models still work in a naive and data-driven way. Understanding that objects fall, for example, would require a model to see lots of examples of objects falling.
Bayesian one-shot learning
This paper suggests a hierarchical generative model that can build whole objects from individual parts. The figure below (copied from the paper) shows an overview of how the algorithm works. It composes characters by combining primitives into more complex objects.
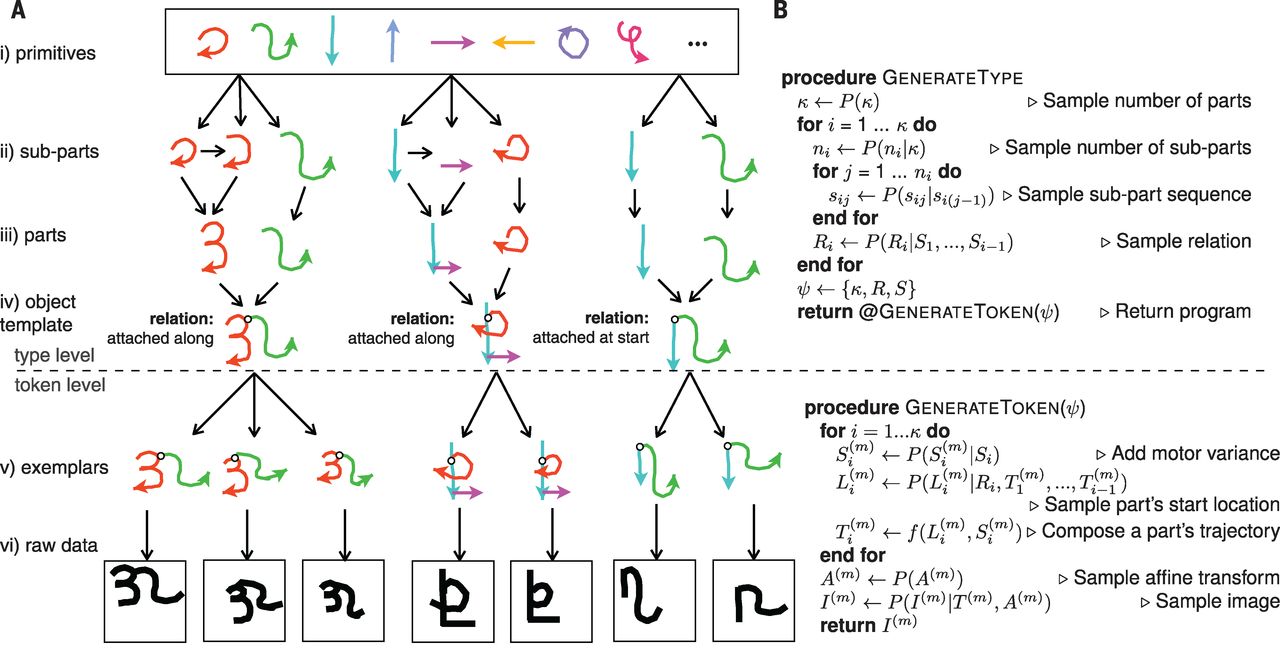
This model has a great advantage in this particular task over deep neural networks which require thousands of examples to train properly. You might ask how is this possible? In simple terms, what Bayesian Program Learning is impose a very strong inductive bias. The number of possible solutions is greatly restricted. Therefore, even a single example can steer the algorithm towards the right solution. In contrast, deep neural networks have a huge solution space with many hyperparameters. Therefore, they require a huge number of examples in order to converge to good solution.
Bayesian Program Learning was applied in this paper only to handwritten characters, but I was wondering whether it would be possible to use it in other domains where there is strong domain knowledge about the problem such as medical diagnoses. In any case, it is exciting to see a completely new approach achieve such a good performance on a task where there are already established solutions out there.