
Black boxes in machine learning
I was reading Kaggle’s No Free Hunch blog the other day. It had an interview from Josef Slavicek who ranked 3rd place on the “Flavours of Physics” competition.
Something that clearly stood out was that Josef is not a data scientist and he managed to get to the third place using an ensemble that combined neural networks and gradient boosted trees. A black box methodology was enough to shoot him to the 3rd place.
Machine learning using black boxes is an interesting idea. Just throw data into the mix and come back with answers. It seems that the majority of competitions in Kaggle are being won by using complicated ensembles, that can easily be used for making predictions out of the box.
Nevertheless, black boxes are useful when the problem has already been defined. They are less useful in situations where the data is available, but the data scientist needs to get creative in order to find ways to extract value from them. Also, more often than not, the relationship between variables needs to be explained in easy-to-understand terms, so that the CEO and any other non-data scientists in the team can make decisions. This is where a black box approach, once again, is not very helpful.
Soft skills vs hard skills in data science
In the end of the day, being a data scientist is as much about soft skills as it is about technical skills. There are however different tribes of data scientists, with some tribes being, for example, more mathematical, and others having better software engineering skills.
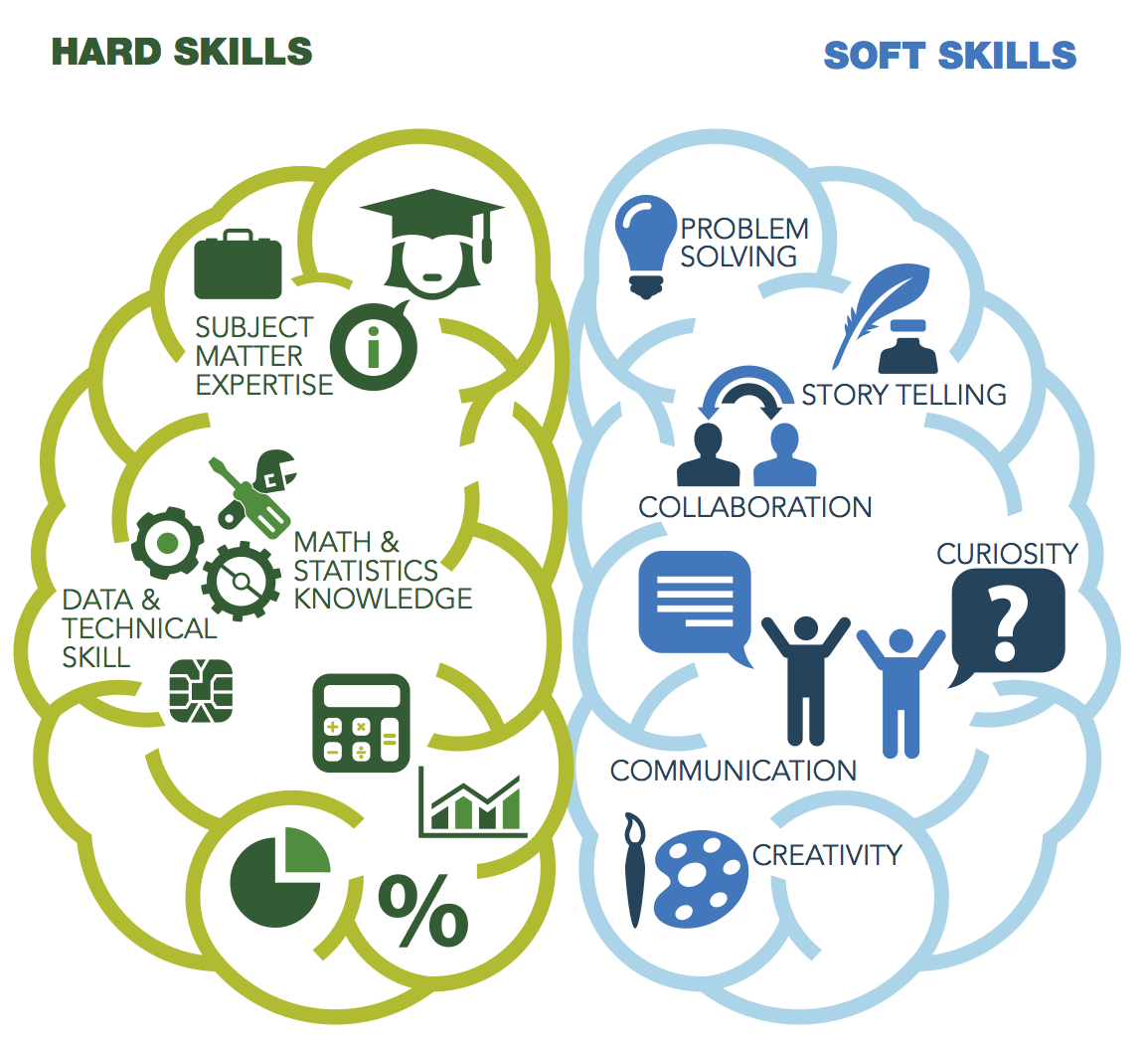
A simple black box, cannot imitate a human’s soft skills. However, what if there was a solution flexible enough, so that it could
- Generate new features from existing ones, similar to how a human would do it.
- Be able to try it many different models, faster than a human would do?
- Create transparent models that can explain how they reach decisions, while still having predictive power.
This is exactly why I developed ADAN.io. ADAN is based on proprietary technology that combines many best practices from the world of automated machine learning and data science. It aims for the best balance between predictive power and transparency. We have already mentioned in the past, how machine learning models can be hard to interpret. This is also something that I have talked about in my videos. ADAN aims for that golden balance between efficiency, transparency and predictive capability.
Feel free to get in touch with any questions or comments.