
In the era of fast-rising interest in big data, data analysis and artificial intelligence, football stakeholders are also looking to machine learning to enhance the success of football throw-ins. Implementing the best analytical strategy on football data not only improves players’ performance but can also save costs for club investors.
Many have asked, “Can machine learning models help improve ball accuracy, precision and retention, leading to scoring after throw-ins?” The answer is not far-fetched if you are looking in the right way.

Discover how you can apply exploratory data analysis and key machine learning models to derive insights from football throw-ins, whether you are a data scientist, football investor or a diehard fan. We crafted this article from a thesis written by a student at Beyond-Machine, a team of seasoned data science, AI, machine learning and programming instructors led by Dr Stylianos Kampakis. If you learn with our self-paced hands-on courses, you will master data science and secure your dream job even without a college degree.
This article uses real-time data from Czech Football League, which you can implement in your league or club to generate valuable insights and make data-driven decisions. Recently, most big leagues are beginning to appreciate the role of throw-ins in players’ performance on the pitch in the team’s overall performances. So, we see an unusual demand for trainers specialising in throw-ins across major leagues such as the English Premier League, Ligue 1, Seri A, and La Liga.
In analysing throw-in data, analysts look at how each attribute, such as throw-in distance, throw-in angle, and timing of taking a throw-in, influences the completeness of throw-in. A critical data analysis of these set pieces further assesses how a successful throw-in can improve ball possession, retention, and goal-scoring probability.

In football analytics, throw-ins are analysed using exploratory data analysis coupled with machine learning models. Analysts collect real-life datasets from leagues, analyse, transform, visualise the data and collaborate with football decision-makers to implement derived insights.
Insights from past projects indicate that shorter throw-ins are more likely to be successful and possession held, while faster throw-ins are more likely to be successful and possession held. Backward throw-ins have a greater probability of success, and possession is kept compared to forward throw-ins. Similarly, a throw-in with a switch taken in the middle or defensive zone also has a better likelihood of scoring and avoiding a conceded goal.
This is only a fragment of how you can maximise data to improve a team’s performance, but data can play more crucial roles in football than in throw-ins. The following sections discuss football analytics as an essential tool football clubs adopt to keep winning in the football industry, significant applications of analytics in football, and the effective use of machine learning models in throw-ins.
What is Football Analytics?
Football analytics entails the application of modern digital data analytics tools to collect, analyse, store, share, visualise and make valuable data-driven decisions using football data generated on-site and off pitches. Over the past decade, data analytics have played invaluable roles in transforming health, e-commerce, banking, research, governance, and sports. Regrettably, people paid little attention to how data analytics could transform the football industry until a few years ago. Clubs that adopted football analytics earlier than their counterparts are already reaping huge benefits.

The truth is that data analytics in football has come to stay and will continue to grow and expand beyond the present scope. Clubs that aim to gain a competitive advantage on and off the pitch embrace data and seize the opportunities in analytics to make huge profits, improve player performance, prevent injuries, and increase their commercial efficiency.
BBC reported that clubs such as Arsenal, Liverpool, Barcelona, and Manchester City are pioneering data analytics and machine learning in sports. This has repositioned them to win matches with better data-driven decisions. Over the years, other clubs not doing so well would eventually discover the goldmine in football analytics and follow suit.
The 3 Best Machine Learning Models for Assessing Football Throw-Ins
In football, “Throw-in” describes a situation when the ball is returned to play by a thrower with their hands. Throw-ins occur when the referee stops the play because the ball leaves the pitch over the sideline. A throw-in is one out of five distinct types of set pieces in football. Other types are penalties, free-kicks, corners, and goal-kicks.
During the throw-in, the player must have both feet on the ground behind the out-of-play sideline, and the ball must be lifted with both hands and delivered back into play. The player out of possession must stay at least two meters in front of the player who delivers the ball. Evaluating the likelihood of a successful pass, the chance of a goal being scored, or any other predictive model in football is now a vital aspect of football analytics. Thus, several prediction models already aid in football decision-making, but this article dives deeper.
Expected Goals (xG) model
The xG model used in football throw-in analytics was introduced by Sam Green. It is a predictive machine learning model used to measure the quality of a chance by calculating the likelihood of scoring for every shot made in the game. When we calculate the xG of a shot, the xG model computes the probability of scoring based on several factors (parameters): the location of the shot; the location of the assist; shot type; assist type; the presence of a dribble of a shooter before the shot; game statement (open play/set piece); transition statement (positional/counterattack); and the tagger’s assessment of the danger of the shot.
All these parameters (plus a few technical ones) are used to train the xG machine learning model on the historical data and predict the probability of the shot being scored. A greater probability indicates a greater likelihood of scoring in the specified parameters. A shot with an xG value of 0.3 is scored in 30% of cases based on all the parameters. Penalties are easier to estimate.
According to Wyscout data, the probability of scoring a penalty is about 76 %. Thus, the penalty xG value has been set to 0.76. Expected Goals against (xGA) is the probability that an opponent’s shot results in a goal based on the attributes given above. For simplicity, an opponent’s xG is assigned as xGA. Expected Goals difference (xGD) is calculated by subtracting the xG value from the xGA value. In the practical part of this thesis, we use the xG model to assess the throw-in performance.
Expected Pass (xPass) model
Matthias Kullowatz developed the Expected Pass (xPass) machine learning model. xPass calculates the probability of a pass being successful. A successful pass is a pass which directly finds the teammate of a passer. To be specific, this model assigns the likelihood to each pass based on several parameters from the dataset: the passer’s location, location of the receiver, angle of the pass, distance of the pass, type of pass (longball/throughball), etc.
The Expected Throw (xThrow) and Expected Retain (xRetain) models
The xThrow and xRetain analytics models are used to predict the chance of a throw-in being complete and the probability of retaining possession following a throw-in based on specific criteria. Eliot McKinley designed these models based on the xPass concept but included a few additional capabilities (parameters). The models used here are identical to those used in Eliot McKinley’s article. Still, they will be trained on a different dataset from a different league, as the objective is to understand the set pattern patterns in many football leagues, such as the Czech Football League.
Exploratory Data Analysis of Football Throw-Ins Using 4 Key Parameters
Before building any football machine learning model, it is essential to have an insight into the effect of numerous factors on the target variable. The features are used in the machine learning model based on the domain expertise in football and previously built models, e.g., Elliot’s expected throw model. In the following figures, we see how the features influence the target variable (completion), possession retention of throw-ins and the likelihood of scoring goals based on xG and Gls statistics, and how they have been changed over time.
1. Throw-in End Location
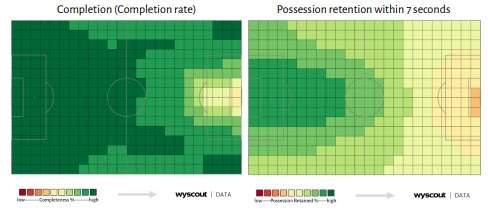
To describe the pitch visualisation, each bin has a value indicating the chance of the target variable being fulfilled. These values were smoothed to make visualisations more interpretable. A grey arrow situated next to the football pitch visualisation represents the direction of the play. The visualisation includes colour bars that describe the mathematical meaning of the colours. Heatmaps were normalised using minimum/maximum as 0/1 to emphasise patterns between these two statistical characteristics.
Regarding the end location of all throw-ins in the dataset, there is a general tendency that the closer the ball is thrown to the opposition’s goal, the less likely a throw-in would be completed. Possession retaining it similarly. Although, the higher chance of throw-in being possession retained is in the central defensive area of the field from a goalkeeper’s perspective, as demonstrated below. However, tracking data containing the coordinates of all players on the field is not available to validate this idea; opposing players’ pressing reduces the chance of possession being kept near the field’s sideline.
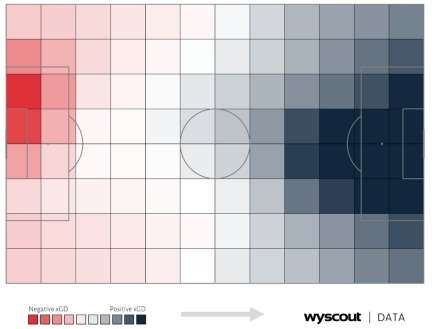
The essential aspect of this data analysis of throw-ins is determining which area has the highest chance of scoring and conceding the goal (xG/xGA) following the throw-in within 15 seconds. The image below represents a difference in average xG and xGA values related to the final location of throw-ins. The negative xGD is shown by red bins, the equal xGD is indicated by white bins, and the positive xGD is expressed by blue bins. Not surprisingly, the xGD value is greater when the throw-in end location is closer to the opposition’s goal, because this corresponds with xGD of all shots.
2. Throw-in Distance
To begin, let us consider throw-in distance. The link between the specified statistical indicators and the throw-in distance inside each zone is visualised in the figure below. The longer the throw-in, the lower the probability of success, which is valid for all zones. In the central zone of the pitch, the probability of the throw-in going directly to a teammate is greater. Ninety percent of throw-ins with fewer than 5 meters are complete. The peak of the completion rate is between 5 and 10 meters. The completion rate of more than 30 meters throw-ins reduces to 78%.
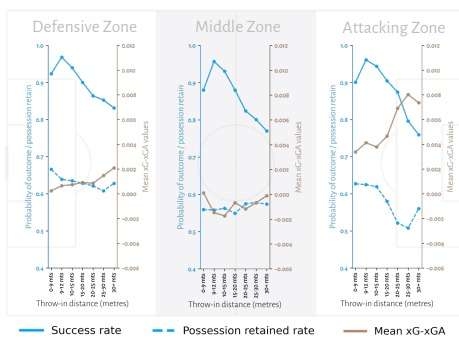
In the defensive zone, possession retention drops as throw-in distance increases, except for the bin with 30+ meters of throw-ins, when possession retention slightly increases. In the middle zone, possession kept within 7 seconds does not vary much among distance intervals; the likelihood fluctuates between 55 and 58 percent, which is a negligible change. Except for the 30+ meters bin for attacking throw-ins, where throw-in angles are more evenly distributed than in the 25-30 meters bin, we can observe a declining trend. In the middle zone, the average xGD is constant. Moreover, bins have a growing tendency toward separating defensive and offensive zones.
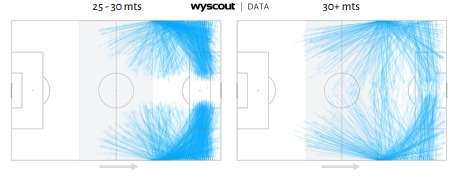
To illustrate, the figure below displays the distribution of long attacking throw-ins for these two previously mentioned bins, with blue arrows indicating the direction of each throw-in. The gray shade denotes three distinct zones. Both bins offer a single pitch to visualise their distribution of throw-ins. The bin with a throw-in length of 25-30 meters contains a higher ratio of progressive throw-ins compared to the bin with a throw-in length of 30+ meters. We already know that, according to the xG model, throwing the ball closer to the opposition’s goal increases the probability of scoring a goal. Based on the fact presented so far, the bin with a length of 30+ meters have a higher probability of possession being kept and has a lower mean xGD than bins with a length of 25-30 meters.
3. Throw-in Angle
Next, we consider the throw-in angle. Throwing sonars are extra components to the figure shown below rather than line plots like in the preceding probability chart above. Each pizza slice represents a bin. The sequence of the bins begins on the left with the bin with an angle of 180-150 degrees and progresses in steps of 30º, as shown in the line plot below. The dark blue pizza slice reflects the completion rate of the bin’s throw-in in the zone, whereas the light blue slice indicates the possession retention rate.
The values in hexagons on the slice ranging from 0 to 100 denote their percentage. As for throw-in sonars, there is no principal difference between each zone. Throw-ins directed toward the opposition’s goal are less likely to be completed or retained.
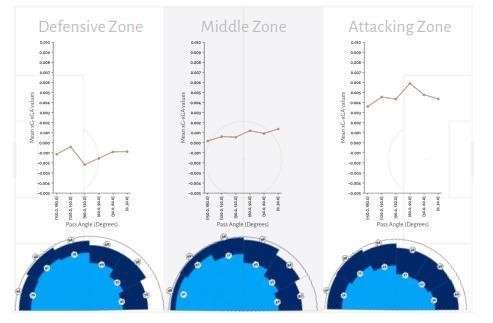
The fact that the angle bin with the 120º–150º is closer to the positive value of the mean xGD in the defensive zone is an interesting factor to consider. This is the angle bin with the greatest likelihood of taking a completed or retained throw-in. The mean xGD of an angle bin with perpendicular and slightly progressive throw-ins lowers to a local minimum. Only then do the two most progressive angle bins (with a range of 0º to 60º) begin to get closer to the positive value of the mean xGD.
In other words, the most successful strategy is to initiate throw-ins from the defensive zone slightly backwards. In the middle zone, a little upward trend over bins suggests that taking more progressive throw-ins slightly increases the likelihood of scoring and avoiding a conceded goal. The rising trend of xGD is valid for the attacking zone. It is worth noting that when a taker, standing in the attacking zone, gets closer to the flag, the xG (as well as success and possession retention rates) trend reverses, making it more advantageous to take perpendicular or slightly backwards throw-ins in terms of throw-in angle probability link.
4. Timing of Taking
Throw-ins in the image below show the probability associated with the characteristic – time since the last action. In all zones, the faster the taker throws, the greater the possibility of success or possession retention; however, the completion rate declines after bins 10-15 seconds after the last action. Big jumps across bins for possession retention tell us that the timing of a throw-in has a more significant impact on possession retention than completeness. Possession retention, on the other hand, operates similarly but with a minor delay of around 5 s. We may attribute domain knowledge, as the opponent can structure a defence within 15 s, making a successful (or possession retained) throw-in more challenging to execute.
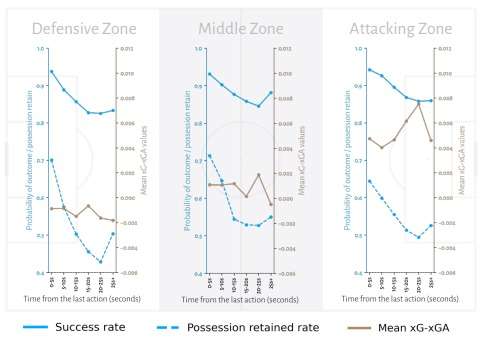
Defensive and middle zones are comparable in terms of the mean xGD. The figure above indicates that timing does not significantly influence xG from throw-ins in these two zones. In the attacking zone, the mean xGD seems to be greater when the taker waits for an ideal option, such as long throw-ins aimed towards the penalty box, which require more time since the taker must run up to produce greater distance and occasionally clean the ball for a better grip. As previously stated, based on the average of xGD values, this kind of throw-in has a better likelihood of scoring than conceding.
Two (2) Major Applications of Data Analysis and Machine Learning in Football
In the past few years, the exponential speed of improvement in the technologies supporting data collection, storage, and analysis has gone together with an exponential increase in the human capital invested in sports analytics. This has seen the quantity and quality of the datasets explode.
In our view, however, the advancements we have seen in the industry in the past five years will be dwarfed by what will happen in the next five. As the datasets have grown and improved, the number of potential applications of data analytics to the game has multiplied, making “football analytics” a generic concept. Below, we try to summarise the main fields of application.
- Injury prevention and rehabilitation
- Performance analysis
- Injury prevention and rehabilitation
From the early days of the 21st century, there has been a consistent improvement and interest in research into clubs’ training loads. The studios have immensely enabled sports scientists to base their analyses on solid foundations. Today, many leading clubs now consistently monitor players’ positions on the pitch and measure their velocity using GPS, which collectively determines the external load or work done by each player. External load tracking through GPS can help predict professional players’ injury risks.

Science Daily’s recent research shows that football injuries can be analytically predicted by looking at the footballers’ workloads during training and matches. Researchers discovered that the greatest injury risk occurred when players accumulated an extremely high number of short bursts of speed during training over three weeks.
Players recorded significantly higher meters per minute in the weeks preceding an injury than their seasonal averages, indicating increased training and gameplay intensity in the lead-up to injuries. Current research in sports biomechanics supports this trend, showing that athletes’ movement patterns deteriorate in a potentially harmful fashion when repeating intense running and direction changes.
- Performance analysis
Big data analysis and machine learning help us to discover counter-intuitive facts about football, upon which we can build an innovative and winning strategy. Football clubs, along with the media and even fans, can, with the support of data, easily understand how a team or player has performed throughout a match or season.
Even the most basic stats, like the number of shots, shots on target, and ball possession, can offer a guide. If we then improve the granularity of the stats and include selected performance indicators, the dataset gradually begins to give a more defined and complete picture of what has happened on the pitch, which enables a detailed analysis of the game. Such granularity can offer a coach more information on how the team has performed and whether it complied with the pre-match instructions.
Performance analysis typically comprises video and data. It is becoming increasingly common to have coaches who can share post-match comments to their players, explaining to them what they did wrong or could improve with the help of video and statistics. At the end of the day, showing objective facts is a more efficient and persuasive way to state a point.
Round Up
Data analytics and machine learning will continue playing huge roles in understanding how football variables, especially throw-ins, impact a team’s performance.
When club owners and officials are empowered with insights from football data, they’d be able to implement data-driven strategies to gain a competitive advantage effectively. Therefore, we look forward to even more digitalised football analytics, whereby data can help improve the efficiency of players, reduce injuries, cut costs, and guarantee wins for teams and leagues.
What’s next?
Want to secure your dream job, switch to a billion-dollar lucrative career or improve your knowledge in your field? Why not learn from the masters? Become data literate by building your knowledge in data science, machine learning, AI, and programming languages at your own pace.
We’ll empower you with relevant data skills to remain relevant in the revolutionised digital economy. Reach out to our team now and discover a world of opportunities in data science, AI, and machine learning.