
Standardising data science
One of the main problems in data science practice is the lack of standardisation regarding procedures and techniques. Coming out of education and moving into the industry you can find yourself with knowledge of various methods and approaches, but no clear guide on best practices. Indeed, data science still largely remains an endeavour largely based on intuition and personal experience.
In other engineering disciplines there are standards to ensure the quality of the final result. Of course, data science is different to engineering disciplines such as civil engineering or computer engineering, where the final output is a physical product. Data science is closer to software engineering, where the lack of physical components means there are smaller construction costs, and considerably more room to experiment and try different things out.

However, in contrast to software engineering, a data science task is almost always defined by a relatively clear goal. I use the word “relatively” because the translation of a business requirement to a data science task can hide many caveats and is something that will be covered in another post. For now I assume that this step has been successful, so the data scientists faces a task such as the following:
1) Predict Y based on a set of variables.
2) Find the main drivers of performance for a business.
3) Predict a time series based on past values.
Each one of these tasks can be measured by one or more clearly defined metrics such as the Root Mean Squared Error, using procedures such as cross-validation. So, while in software engineering agile methodologies (such as SCRUM) have dominated the field, as a response to ever changing requirements or problems, data science has more to gain by being closer to the scientific method: an iterative cycle of hypothesis and tests.
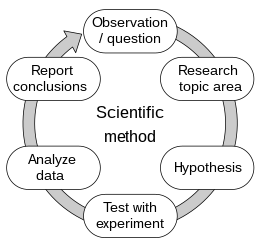
Data science protocols for standardisation
Even though it is possible to standardise this methodology for particular problems, this has not been done until now. There are efforts to compare different algorithms and workflows on different problems such as OpenML . OpenML is an excellent idea, but it is more geared towards comparisons, instead of simple theory and practice driven recipes which can be readily used by practitioners.
The approach I introduce right here, called data science protocols is a way to define data science workflows, so that three main requirements are fulfilled:
1) Evidence based: The workflow is based either on evidence gained either through the literature or experience.
2) Assumptions-Test-Insights: There is a clear description of the assumptions behind the workflow, a clear testing procedure and a clear explanation of the what insights the failure or the success of the protocol means.
3) Versioning: There is a clear way to dispute or improve the protocol.
So, data science protocols are like recipes, but more formalised. Data science protocols can be used to train new data scientists faster, speed-up the workflow, since the wheel does not have to be re-invented each time, and also perform data science in a more objective and evidence-based way.
Having said that, I have done some example work on how data science protocols could be used in linear regression for example. I have also done work in using data science protocols for automating data science through my project ADAN.io.
Let me know what you think in the comments or simply get in touch!