It is impossible to become a data scientist without programming. However, you don’t have to be a data scientist to use data science! The market around data science, machine learning and analytics has matured enough to the point where there are many products out there to run data science algorithms without being a data scientist. Here are some of them, including ADAN.io, a product I have been working on for 2 years now, designed to automate 80% of the data science process. Read below for more details, and the pros/cons of each product!
IBM SPSS (The Statistical Package For the Social Sciences)
SPSS has been a very popular in the social sciences for decades. It offers a very good coverage of the most popular algorithms in statistics. SPSS has an interface that looks like a data table, where the user can record or load the data. The user can run all popular statistical significance tests (ANOVA, t-test, etc.), or models (linear regression, logistic regression, the generalized linear model etc.). Finally, SPSS also supports some machine learning models, such as neural networks. However, its coverage of machine learning models is not that great, as it is geared mainly towards statistics.
WEKA: Open source data mining and machine learning software

Weka is an open source software written in Java by the University of Waikato. It has a very simple GUI, but do not be tricked as it is very powerful. It has a very good coverage of all popular machine learning models, from Support Vector Machines to Random Forests to Ensemble Methods. It also has some algorithms coming from the field of data mining such as association rule mining (also called market basket analysis). Weka is actually a very popular way to teach machine learning and data mining to beginners. There is an introductory textbook for data mining that has been based on Weka called Data Mining: Practical Machine Learning Tools and Techniques. The main drawback behind Weka is that it does not offer very good data load or transformation capabilities. Also, it can be slow at times.
Rapidminer
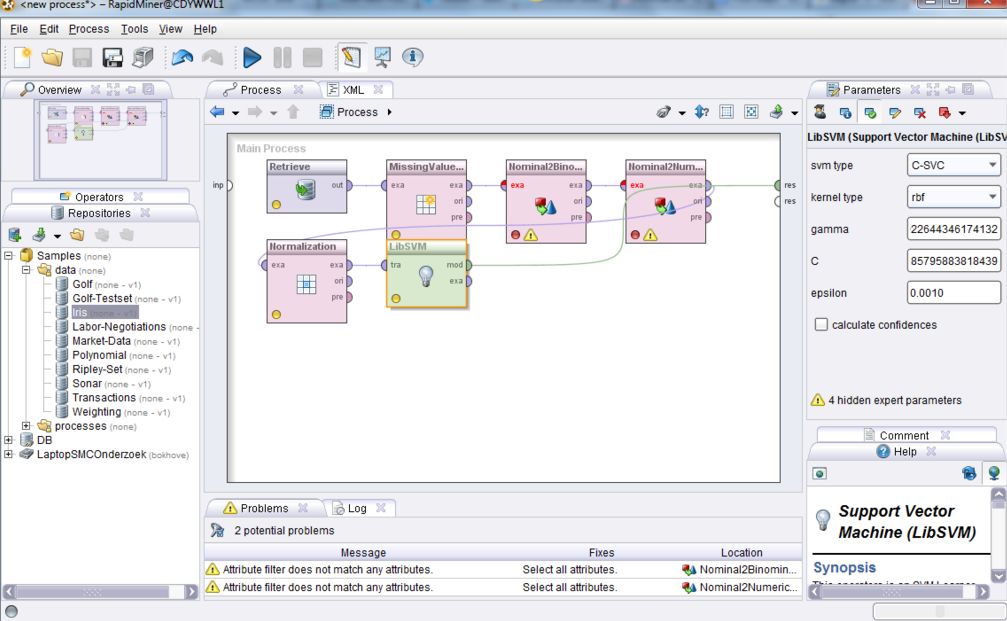
Rapidminer started in 2006 as an open source project called Rapid-I, but since then it has raised more than $30 million in investment. The latest versions require a license to run. RapidMiner offers a plug-and-play drag-and-drop interface that covers the full analytics pipeline. You can load any kind of data, perform preprocessing and feature selection and then try out different models, all without typing a single line of code. RapidMiner also now allows the execution of custom Python and R scripts. RapidMiner is very powerful and easy to use, but it does not come cheap with the cheapest license being at $2500/user for a year.
Azure ML Studio
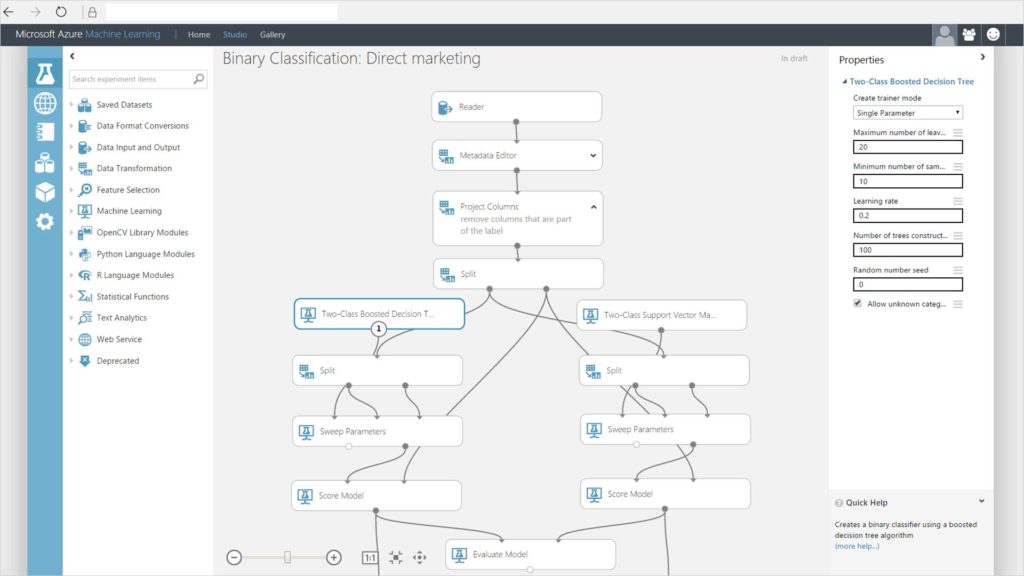
The Azure ML Studio is Microsoft’s answer for a machine learning platform that can work without the user needing to program anything. The Azure ML Studio offers an interface similar to Rapidminer with drag-and-drop components, that can form a full pipeline. An added benefit is that it also supports R. It is part of Microsoft’s Azure offering, so if you are keen on their technological stack, then the Azure ML Studio could potentially be a great choice.
KNIME
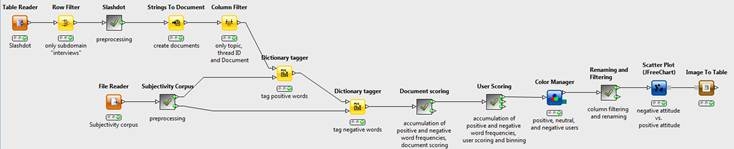
KNIME is another solution that is similar to Rapidminer, in the sense that it provides a drag-and-drop GUI. One of the great benefits of KNIMe is that it is open source and free. On their website the provide many examples of use cases, from sentiment analysis to churn analysis.
IBM Watson
IBM Watson is one of the most popular solutions for those who want to do data science without programming. IBM Watson offers a multitude of analytical capabilities, from sentiment analysis to image classification. IBM Watson Studio is a tool within their suite of services that offers dashboard and pipeline designing capabilities, without requiring any coding skills. It also integrates with RStudio and Python Jupyter notebooks, so data scientists with coding skills can also combine their capabilities with the platform.
Driverless AI by H2o and DATA ROBOT
Both Driverless AI by H20 and DataRobot are Auto-ML solutions, that is solutions that try to replace a large part of a data scientist’s work through automation. Whereas the can be used to perform data science without programming, they still assume that the user is familiar with terminology such as XGBoost, or elastic nets. So, they are best used by a data science team that wants to optimise its performance.
DataX (former ADAN)
I have also been active in the area of Auto-ML for some time, through my project DataX. ADAN combined all the best features of the latest research in automated machine learning. It can extract the relevant features very fast from 1000s of variables, combine them in new features and come up with excellent models. Its great advantage, is that the models produced by ADAN are also easily interpretable, in contrast to most machine learning models out there. Feel free to get in touch if you are interested to learn more.