
Data cleansing is eliminating or correcting erroneous, incomplete, redundant, or poorly formatted data from a dataset.

Routine business operations and large system migrations can impact data reliability. Data cleansing and exploratory analysis take up 80% of data scientists’ time, which is a very common theme discussed in some of the best data science blogs? What if data scientists could spend most of their time performing higher-level jobs that more accurately reflected their pay?
Each new dataset presents a fresh set of problems for the junior data scientist. It appears impossible to automate data cleansing. Decision-makers and stakeholders are unaware of the wasted resources on the issue since it is so far away from them.
Although automation seems right, they might need to appreciate the difficulties fully. Even though it costs a lot of money, it typically is not a top priority in many firms.
However, code can categorize missing values and deal with them efficiently. Automating the data cleansing stage can save time and eliminate tedious, repeated chores, making your data scientists happier. Here, we will go over the main problems and solutions.
Create a Snapshot of your data
It would help if you first make a summary table for each feature, whether it is numerical, categorical, text, or mixed. Get the top 5 values together with their frequencies for each element. This can easily help you detect things such an incorrect or vacant zip codes, for example values like 99999.
Also, this would help you detect values such as NaN (not a number), N/A, improper date formats, missing values (blank), and special characters.
Text might have problems with accented letters, commas, dollar signs, percentage signs, and other symbols. This can mess up regular expressions, as well as machine learning algorithms such as deep neural networks.

For numerical features, calculate the numerical features’ minimum, maximum, median, and different percentiles. This can quickly help you detect outliers, such as extreme values. For example, if you have a column representing a feature such as weight or height, it will be easy to detect rows with unreasonable values (e.g. negative height). These can often be automated through the use of automated quality test rules.
If you are using Pandas, the info() function is very helpful in this scenario.
Further tips for data cleaning
Examining how different traits interact is the next stage. Make a list of all cross-correlations between any two features. Quite often, if a correlation is extremely high (e.g. close to 1), then they might be duplicate features. In this case it might be best to remove one of them, in order to avoid redundant information.
Use checksums for encrypted fields like credit card numbers or ID fields if at all practicable. Look for keys or IDs that are the same or almost identical. Additionally, the same person may be represented by two separate IDs. This can show up errors in your data. Working with a list of frequent mistakes can be beneficial.
Additionally, whenever possible, collect data using pre-populated fields in web forms rather than having consumers manually type in details like their state, city, zip code, or date. Look for fields that need to be aligned. Data like URLs are parsed and stored in CSV files before being published in databases, which is common in NLP challenges.
Do dates have various encodings? This occurs when different data sets from multiple sources are combined. Dates should be uniform to solve this problem. A good way to detect issues with date encodings is to use the pd.to_datetime function. It will often fail if it cannot detect a consistent format. However, it still pays off to check dates manually.
Once the data has been cleaned, you can include data into your machine learning system and use your regular algorithms to handle it.
Addressing the Issues
There are some easy improvements that you can make. For instance, if NaN is how you represent missing data, you might use a blank instead—or make a table that details every possible encoding scheme for missing data. This will ensure that you never misrepresent a missing value.
Using a dictionary or comparing cities with zip codes can help correct errors or misspelled names. Such a dictionary can be created using keyword associations and frequency data.
Regular expressions or other methods can detect split fields, such as those caused by a comma incorrectly used as a field separator, and then correctly realign misaligned fields. Combine features and IDs that are duplicates.
A pretty common solution for missing values is imputation. The simplest form of imputation is to replace the missing value with the mean (for numerical attributes) or the mode (for categorical ones). There are also more advanced methods of imputation using techniques such as k-nearest neighbours. The MICE package in R can help you with this.
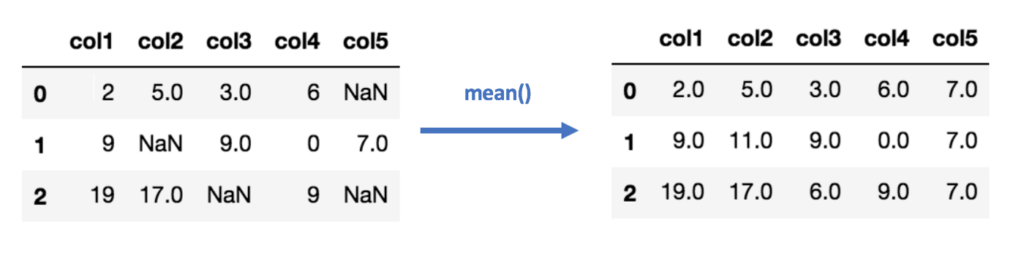
Errors, however, are only sometimes fixable. You can disregard a portion of the dataset in this situation. However, if you find yourself discarding more than 25% of the data, you might want to pause your project and question the data collection process.
Final Verdict
You must be able to profile and identify the poor data before you can clean it up. Afterward, take corrective action to produce a tidy, standardized dataset. Machine learning and AI can automate operations at different phases of the data purification process while also making more accurate findings.
Machine learning is an exciting field with a lot of opportunities for innovation. But no matter how excited you are, tackling machine learning problems can take time and effort. You need to know so many things before you can even start. But that’s not the case! Our blog posts will walk you through how to solve machine-learning problems quickly and easily.

If you want to learn more about data science or become a data scientist, make sure to get in touch. Also, make sure to check out our data science bootcamp Beyond Machine. We are the only program in the market that helps you find a job in data science, and even makes job applications for you!