
In this article, we will be covering a Scikit learn tutorial in which we will dig deep into the Scikit-Learn library and see how we can use python and Scikit-Learn to solve machine learning problems.
Scikit-Learn (Sklearn) is a free, open-source, and popular python package. Sklearn has multiple uses but it is more prominently used for machine learning and statistical analysis.
It comes with several valuable tools that can aid in solving various problems like classification, regression, and clustering.
Background
Scikit-learn started off as a Google Summer of Code project with the name scikits.learn by David Cournapeau.
Most of the code is written in python but some of the code was written in cython to optimize the library.
It works well with NumPy, SciPy, and Matplotlib.
Features
If you want to manipulate, load or clean data Sklearn isn’t the optimal choice. Instead, if you’re seeking a package that can help in the data modeling phase, Sklearn is a pretty good choice.
Let’s take a look at some of the features of the Scikit-learn package.
- Supervised Learning Algorithms
- Unsupervised Learning Algorithms
- Cross Validation
- Dimensionality Reduction
- Hyperparameter Tuning
- Ensemble Methods
- Feature Selection and Extraction
Let’s go through them in detail.
- Supervised Learning Algorithms
Sklearn comes with a number of supervised learning algorithms such as Decision Trees, Logistic Regression, Linear Regression, Support Vector Machines (SVM), etc.
- Unsupervised Learning Algorithms
The Scikit-Learn package also has numerous useful unsupervised learning algorithms such as Principal Component Analysis (PCA), Clustering, etc.
- Cross Validation
Using Scikit-Learn, one can perform cross-validation of their model’s accuracy by testing their model on unseen data.
- Dimensionality Reduction
Scikit-Learn allows one to reduce the dimensions of the user’s dataset which can help in feature selection.
- Hyperparameter Tuning
Sklearn allows you to tune the hyperparameters and find the best parameters for your models.
- Ensemble Methods
Ensemble methods is a technique in which one can combine the results of several supervised algorithms. It helps make decisions by voting or averaging the output of multiple models.
- Feature Selection and Extraction
The Scikit-Learn package can also be used in identifying more important features in the data and helping create supervised models.
Scikit-Learn Tutorial
Now that we’ve briefly taken an overview of what Scikit-learn is let’s take a look at a python tutorial with Scikit-learn.
Dataset
For the purpose of this example, we will be using the iris dataset.
The dataset consists of 3 classes with each class having 50 instances. Only one of the three classes is linearly separable. It consists of 4 attributes as well.
Problem
From the dataset, we can conclude this is a supervised learning classification problem. So, we will be using a supervised learning algorithm.
Sklearn comes with a series of classification problems. We will be using the Decision Trees classifier algorithm for the sake of this problem.
Now, let’s take a look at the code:
First, we import the necessary libraries
import pandas as pd import numpy as np from sklearn import datasets from sklearn import metrics from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import train_test_split import seaborn as sns from matplotlib import pyplot as plt
Now we will be loading a dataset. Sklearn comes with a number of useful datasets, we will be using the iris dataset.
data = datasets.load_iris() df = pd.DataFrame(data.data, columns=data.feature_names) df['target'] = data.target
Let’s take a look at our data and see what kind of data we have, how many samples of each class do we have.
print(df.dtypes) print(df.head()) print(df.tail()) print(df['target'].value_counts())
Now we will be splitting our data into train and test sets and shuffling the samples randomly. We perform this step so that during predicting step, our model gets unseen data.
X = df.drop(columns=['target']) y = df['target'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
We will be creating the model that we want to use and fitting it on our data. We will be using the train data that we had split.
dt_model = DecisionTreeClassifier() dt_model.fit(X_train, y_train)
Let’s use the model that we had trained to make some predictions on the test set.
preds = dt_model.predict(X_test)
We will be visualizing the results now so we can take a look at the confusion matrix.
print(metrics.classification_report(y_test, preds)) print(metrics.confusion_matrix(y_test, preds)) sns.heatmap(metrics.confusion_matrix(y_test, preds), xticklabels=data.target_names, yticklabels=data.target_names, annot=True, linewidths=0.1, fmt="d", cmap="YlGnBu") plt.title("Confusion matrix Test", fontsize=15) plt.ylabel("True label") plt.xlabel("Predicted label") plt.show()
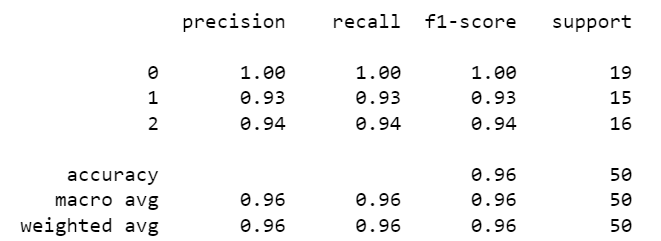
Classification Report
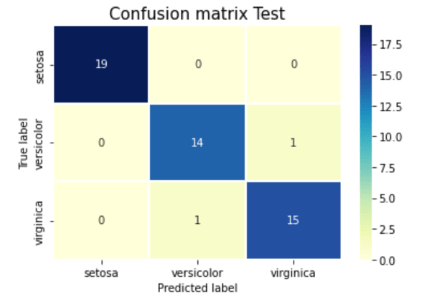
Confusion Matrix
Results
From the classification report and confusion matrix, it is evident that we were able to get pretty decent results on the test set.
We were able to get 100% precision on 0 (sertosa), 93% precision on 1 (versicolor) and 94% on 2 (virginica).
Conclusion: Where can I learn data science?

In this Scikit-Learn tutorial, we covered the many features this package has to offer and how we can utilize Scikit-Learn efficiently in our problems.
Now that you have discovered and explored data science and how you can fit into this evolving field, it’s time to take action. There are numerous paths to gaining data science skills either as a new graduate or a working adult without prior experience in data science. One such effective way to break into data science and secure a lucrative role in your dream company is to take a professional interactive course in data science. We can help you get started. We have several affordable self-paced courses you can start with from basics to advanced.
You will become an expert in data science if you take our courses taught by award-winning data scientists, statisticians, data engineers, and developers. Whether you are a business analyst, STEM graduate, stay-at-home parent, programmer, or undergraduate looking to upskill or switch to a more lucrative role in data science, our courses are for you. We would teach you from scratch if you never experienced data science. This is to ensure that you acquire all prerequisite technical, qualitative, and quantitative knowledge required to deliver excellently as a data scientist.
At completion, we guide you through a project of your choice, mentor, coach, and support your future career with a compelling CV and topnotch LinkedIn makeover to help you smash your first data science job interview.
You can go ahead now to enrol in our data science course and start your journey towards landing your dream job and boosting your income.