Do you want to become data scientist?

Do you want to become a data scientist and pursue a lucrative career with a high salary, working from anywhere in the world? I have developed a unique course based on my 10+ years of teaching experience in this area. The course offers the following:
- Learn all the basics of data science (value $10k+)
- Get premium mentoring (value at $1k/hour)
- We apply to jobs for you and we help you land a job, by preparing you for interviews (value at $50k+ per year)
- We provide a satisfaction guarantee!
If you want to learn more book a call with my team now or get in touch.
Decision trees in machine learning
Modern machine learning algorithms are revolutionizing our daily lives. For instance, large language models like BERT are powering Google Search, and GPT-3 is powering many advanced language applications.
Today, building complex machine learning algorithms is easier than ever. However, no matter how complex a machine learning algorithms get, it falls under one of the following learning categories:
- Supervised learning
- Unsupervised learning
- Semi-supervised learning
- Reinforcement learning
Decision trees are one of the oldest supervised machine learning algorithms that solves a wide range of real-world problems. Studies suggest that the earliest invention of a decision tree algorithm dates back to 1963.
Let us dive into the details of this algorithm to see why this class of algorithms is still popular today.
What is a Decision Tree?
The decision tree algorithm is a popular supervised machine learning algorithm for its simple approach to dealing with complex datasets. Decision trees get the name from their resemblance to a tree that includes roots, branches and leaves in the form of nodes and edges. They are used for decision analysis much like a flowchart of if-else based decisions that lead to the required prediction. The tree learns these if-else decision rules to split the data set to make a tree-like model.
Decision trees find their usage in the prediction of discrete results for classification problems and continuous numeric results for regression problems. There are many different algorithms developed over the years, like CART, C4.5 and ensembles, such as random forest and Gradient Boosted Trees.
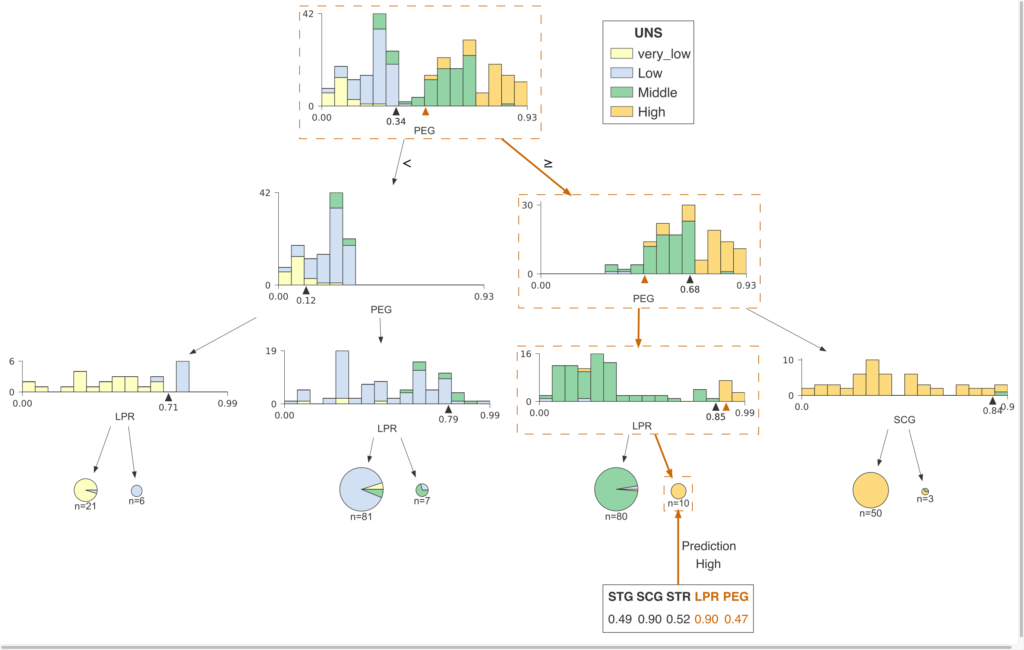
Dissecting the Various Components of Decision Tree
The goal of a decision tree algorithm is to predict an outcome from an input dataset. The dataset of the tree is in the form of attributes, their values and the classes to predict. Like any supervised learning algorithm, the dataset is divided into training and test sets. The training set defines the decision rules that the algorithm learns and applies on the test set.
Before getting into the steps of a decision tree algorithm, let us go through the components of a decision tree:
- Root Node: It is the starting node at the top of the decision tree that contains all the attribute values. Root node splits into decision nodes based on the decision rules that the algorithm has learnt.
- Branch: Branches are connectors between nodes that correspond to the values of attributes. In binary splits, the branches denote true and false paths.
- Decision Nodes/Internal Nodes: Internal nodes are decision nodes between root node and leaf nodes that correspond to decision rules and their answer paths. Nodes denote questions and branches show paths based on relevant answers to those questions.
- Leaf Nodes: Leaf nodes are terminal nodes that represent the target prediction. These nodes do not split any further.
Following is a visual representation of a decision tree and its above mentioned components:
A decision tree algorithm goes through the following steps to reach the required prediction:
- The algorithm starts at the root node with all the attribute values.
- The root node splits into decision nodes based on the decision rules that the algorithm has learnt from the training set.
- Passing through internal decision nodes through branches/edges based on questions and their answer paths.
- Continue the previous steps until leaf nodes are reached or until all attributes have been used.
To select the best attribute at every node, splitting is done according to one of the two attribute selection metrics:
- Gini index measures the Gini impurity to indicate the algorithm’s likelihood of wrong classification of random class labels.
- Information gain measures the improvement in entropy after splitting to avoid a 50/50 split of prediction classes. Entropy is a mathematical measure of impurities in a given data sample. chaos in the decision tree indicated by an almost 50/50 split
Flower Classification Tutorial With Decision Tree Algorithm
With the above-mentioned basics in mind, let us proceed to implementation. For this article, we will implement a decision tree classification model in Python using the Scikit-learn library.
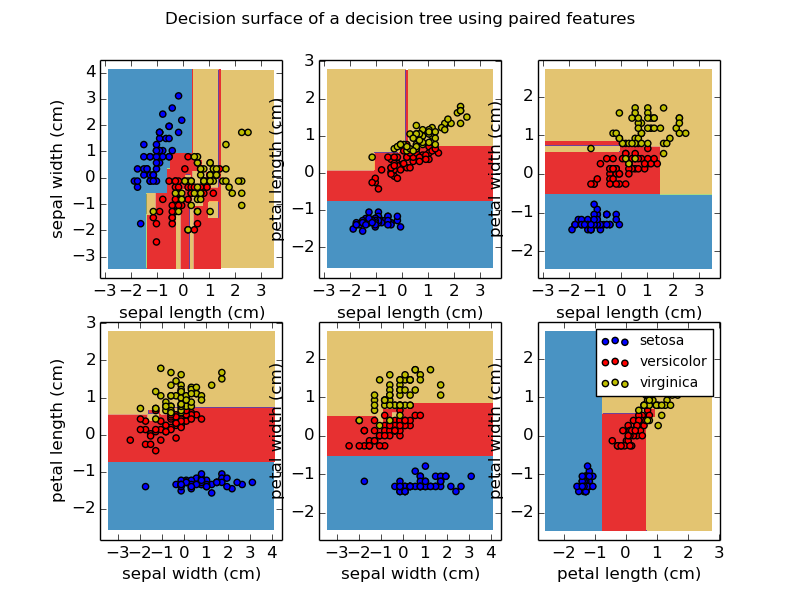
About the dataset: The dataset for this tutorial is an iris flower dataset. Scikit learn dataset library already has this dataset so no need to load it externally. This dataset includes four iris attributes and their values that will be input to predict one of the three types of iris flowers.
- Attributes/features in the dataset: Sepal Length, Sepal width, Petal Length, Petal width
- Prediction labels/flower types in the dataset: Setosis, Versicolor, Virginica
Following is a step-by-step tutorial for python implementation of decision tree classifier:
Importing libraries
To begin with, the following piece of code is importing the required libraries to perform the decision tree implementation.
| import pandas as pd import numpy as np from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier |
Loading the iris dataset
The following code is using the load_iris function to load the iris dataset, from the sklearn.dataset library, in the data_set variable. Print the iris types and features in the next two lines.
| data_set = load_iris() print(‘Iris plant classes to predict: ‘, data_set.target_names) print(‘Four features of iris plant: ‘, data_set.feature_names) |
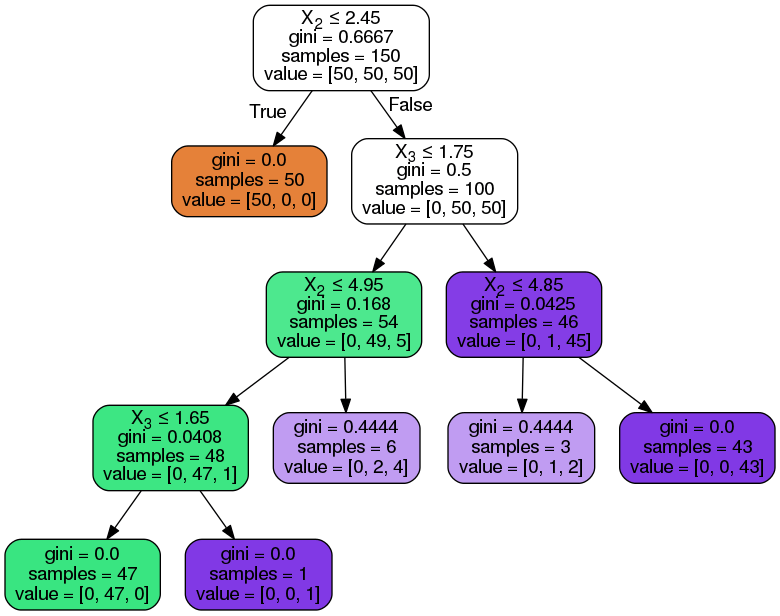
Separating attributes and labels
The following lines of code are separating the features and types of flowers and storing them in variables. The shape[0] function is determining the number of attributes stored in the X_att variable. The total number of attribute values in our dataset is 150.
| #Extracting data attributes and labels X_att = data_set.data y_label = data_set.target print(‘Total examples in the dataset:’, X_att.shape[0]) |
We can also create a table visualization for a portion of attribute values in the dataset by adding values in the X_att variable to a DataFrame function from the pandas library.
| data_view=pd.DataFrame({ ‘sepal length’:X_att[:,0], ‘sepal width’:X_att[:,1], ‘petal length’:X_att[:,2], ‘petal width’:X_att[:,3], ‘species’:y_label }) data_view.head() |
Splitting the dataset
The following code splits the dataset into training and testing sets using the train_test_split function. The random_state parameter in this function is used to give a random seed to the function to give the same results for a given dataset at every execution. The test_size indicates the size of the test set. 0.25 indicates the division of 25% of test data and 75% of training data.
| #Splitting the data set to create train and test sets X_att_train, X_att_test, y_label_train, y_label_test = train_test_split(X_att, y_label, random_state = 42, test_size = 0.25) |
Applying the decision tree classification function
The following code is implementing the decision tree by creating a classification model using the DecisionTreeClassifier function with the criterion set as ‘entropy’. This criterion sets the attribute selection measure to Information gain. Following that, the code fits the model to our training set of attributes and labels.
| #Applying decision tree classifier clf_dt = DecisionTreeClassifier(criterion = ‘entropy’) clf_dt.fit(X_att_train, y_label_train) |
Calculating model accuracy
The following piece of code is calculating and printing the accuracy of the decision tree classification model on the training and test sets. To calculate the accuracy score we use the predict function. The accuracy was 100% for the training set and 94.7% for the test set.
| print(‘Training data accuracy: ‘, accuracy_score(y_true=y_label_train, y_pred=clf_dt.predict(X_att_train))) print(‘Test data accuracy: ‘, accuracy_score(y_true=y_label_test, y_pred=clf_dt.predict(X_att_test))) |
Real-World Decision Tree Applications
Decision trees find their applications across many industries in their decision-making processes. Common applications of decision trees are found in the financial and marketing sectors. They can be used for:
- loan approvals,
- spending management,
- customer churn predictions,
- new product viability, and more.
How can Decision Trees be improved?
In conclusion to this basic background and implementation of decision trees, it’s safe to assume that they are still popular for their interpretability. The reason decision trees are easy to understand is that they can be visualized and interpreted by humans. Therefore, they are an intuitive approach to solving machine learning problems, while also making sure that the results are interpretable. Interpretability in machine learning is a bit topic which we have discussed in the past, and it is also connected to the up and coming theme of AI ethics.
Like any machine learning algorithm, decision trees can also be improved to avoid overfitting and biases towards the dominant prediction class. Pruning and ensembling are common approaches to overcoming the decision tree algorithm’s shortcomings. Even with these shortcomings, decision trees are the foundation of decision analysis algorithms and will always stay relevant in machine learning.
Do you want to become data scientist?

Do you want to become a data scientist and pursue a lucrative career with a high salary, working from anywhere in the world? I have developed a unique course based on my 10+ years of teaching experience in this area. The course offers the following:
- Learn all the basics of data science (value $10k+)
- Get premium mentoring (value at $1k/hour)
- We apply to jobs for you and we help you land a job, by preparing you for interviews (value at $50k+ per year)
- We provide a satisfaction guarantee!
If you want to learn more book a call with my team now or get in touch.