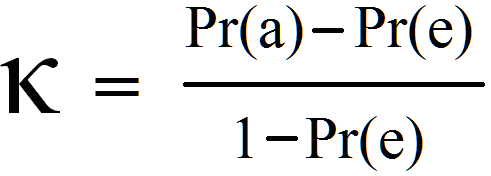
Cohen’s Kappa statistic is a very useful, but under-utilised, metric. Sometimes in machine learning we are faced with a multi-class classification problem. In those cases, measures such as the accuracy, or precision/recall do not provide the complete picture of the performance of our classifier.
In some other cases we might face a problem with imbalanced classes. E.g. we have two classes, say A and B, and A shows up on 5% of the time. Accuracy can be misleading, so we go for measures such as precision and recall. There are ways to combine the two, such as the F-measure, but the F-measure does not have a very good intuitive explanation, other than it being the harmonic mean of precision and recall.
Cohen’s kappa statistic is a very good measure that can handle very well both multi-class and imbalanced class problems.
Cohen’s kappa is defined as:
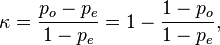
where po is the observed agreement, and pe is the expected agreement. It basically tells you how much better your classifier is performing over the performance of a classifier that simply guesses at random according to the frequency of each class.
Cohen’s kappa is always less than or equal to 1. Values of 0 or less, indicate that the classifier is useless. There is no standardized way to interpret its values. Landis and Koch (1977) provide a way to characterize values. According to their scheme a value < 0 is indicating no agreement , 0–0.20 as slight, 0.21–0.40 as fair, 0.41–0.60 as moderate, 0.61–0.80 as substantial, and 0.81–1 as almost perfect agreement.
Cohen’s kappa is provided by many software packages and libraries such as caret, Weka and scikit-learn. So, next time you face a problem with imbalanced classes or a multi-class classification problem give it a go! In the meantime, if you want to read about another interesting metric, but this time in regression, make sure to check my article about the concordance correlation coefficient.
Do you want to become data scientist?

Do you want to become a data scientist and pursue a lucrative career with a high salary, working from anywhere in the world? I have developed a unique course based on my 10+ years of teaching experience in this area. The course offers the following:
- Learn all the basics of data science (value $10k+)
- Get premium mentoring (value at $1k/hour)
- We apply to jobs for you and we help you land a job, by preparing you for interviews (value at $50k+ per year)
- We provide a satisfaction guarantee!
If you want to learn more book a call with my team now or get in touch.
References
Landis, J.R.; Koch, G.G. (1977). “The measurement of observer agreement for categorical data”. Biometrics 33 (1): 159–174