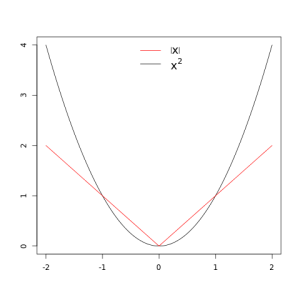
In our first post about performance measures we talked about Cohen’s kappa. This time I want to talk about two different measures: The Root Mean Squared Error (RMSE) and the Mean Absolute Error (MAE).
The RMSE is defined as:
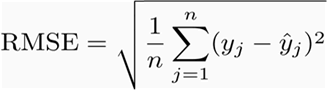
It is one of the most common metrics in regression, both in statistics and machine learning. Why is it so popular? One of the main reasons is that it is very easy to differentiate. This makes it easy to use in conjunction with derivative-based methods such as gradient descent.
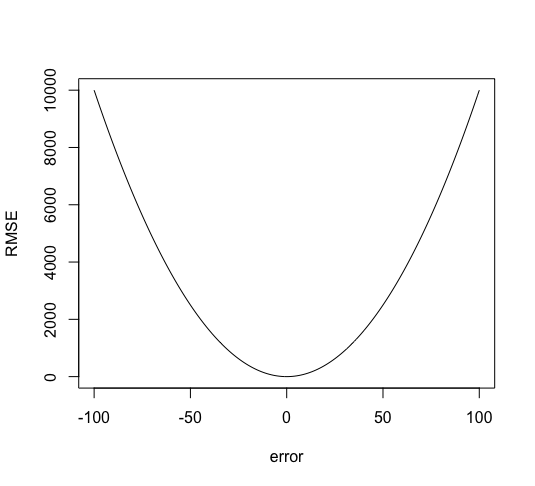
Another important property of the RMSE is that the fact that the errors are squared means that a much larger weight is assigned to larger errors. So, an error of 10, is 100 times worse than an error of 1.
The MAE is simply defined as:
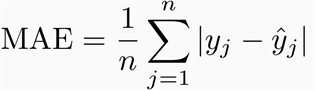
And it looks like this:
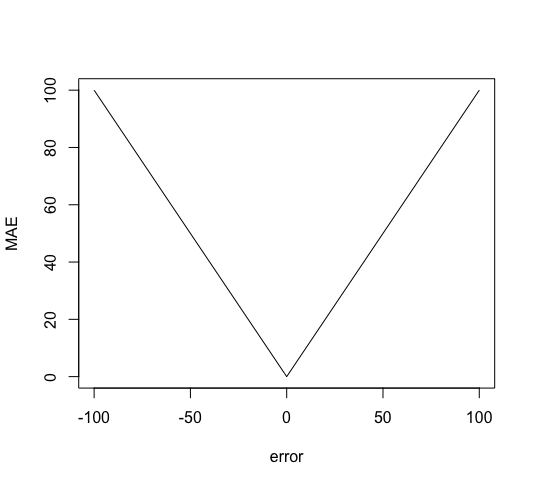
When using the MAE, the error scales linearly. Therefore, an error of 10, is 10 times worse than an error of 1.
In both cases, the error is defined in the same unit of measurement as the target variable.
So, the question you need to ask yourself, are higher errors really that important? This actually depends on the domain of your problem. So, let’s take two different modelling problems:
- Forecasting demand for a retailer’s goods.
- Building a statistical model of the temperature of a controller device in a power plant.
In the first case, the error scales linearly. If the model forecasts that 10 units less will be sold, than they actually are, then the retailer is losing the profit of these 10 units. If the model predicts higher demand, then the retailer might find that there is some surplus stock, but if the retailer is in a domain where the goods do not expire (e.g. electronics), then this is not a big deal.
In the second scenario, we have a controller device that we know is at danger of breaking down when the temperature gets too high. In that case the error is highly non-linear. Small deviations from the predicted temperature are not important, but if the model makes 1 large prediction, then the whole system could face catastrophic failure.
Therefore, the RMSE is better suited for the second scenario, whereas the MAE is better suited for the first. Choosing the right error metrics can be an important part of the machine learning pipeline. It affects the way the results are communicated, as well as the way the model is optimised. If you are a student of machine learning, you might want to check some of my courses where I talk about performance metrics and many other topics.
Do you want to become data scientist?

Do you want to become a data scientist and pursue a lucrative career with a high salary, working from anywhere in the world? I have developed a unique course based on my 10+ years of teaching experience in this area. The course offers the following:
- Learn all the basics of data science (value $10k+)
- Get premium mentoring (value at $1k/hour)
- We apply to jobs for you and we help you land a job, by preparing you for interviews (value at $50k+ per year)
- We provide a satisfaction guarantee!
If you want to learn more book a call with my team now or get in touch.