
QA Testing
Most people are familiar with the term Quality Assurance Testing in engineering. The definition of Q&A Testing given by techtarget is:
“In developing products and services, quality assurance is any systematic process of checking to see whether a product or service being developed is meeting specified requirements. […] A quality assurance system is said to increase customer confidence and a company’s credibility, to improve work processes and efficiency, and to enable a company to better compete with others. […] Today’s quality assurance systems emphasize catching defects before they get into the final product.”
Why is Q&A testing a good idea? In engineering, there are many things that could go wrong, and they only way to know that a system will work correctly is through testing. To understand how complicated testing can be, here are just some types of software testing being used in the industry:
There are even international standards set up on QA testing for software.

Quality and assurance in data science
Now, how many of you have heard of QA testing in analytics? Probably only a few. Every data scientist, however, is familiar with the concept of cross-validation, using parts of your dataset in order to test generalization performance. In simple words, use your dataset to get an estimate of how well the model will do in the real world. So, what is the difference between cross-validation and QA testing?
QA testing has an inherent business component in it. It’s not just about making sure that the system works properly, but also that it achieves the goal to a certain standard. To that end, many data scientists fall to these mistakes.
1) Not choosing an appropriate metric for the task at hand. We’ve already discussed about this issue in the past in the article about performance measures in predictive modelling.
2) Not making sure that the dataset at hand is representative of the real world. A common problem is concept drift. The concept that is being modelled has changed due to external factors. Think for example how much different the economy and investor behavior was before the 2008 financial crisis and after that. Applying a model built in 2006 to data from 2009 would probably yield wrong results.
3) Overfitting or underfitting are two other very common problems in machine learning and predictive analytics. We use cross-validation to guard against that, but only through excessive testing can we be sure of our model’s performance.
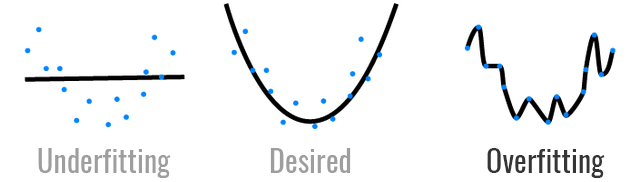
Overfitting and underfitting are two common problems in machine learning that we need to guard against.
Overfitting describes the phenomenon where a machine learning model performs significantly worse in the real world, than when it was trained. This takes place because the model has confused the signal with the noise. It is one of the most pervasive issues in machine learning.
4) Not understanding how the model will translate in business terms. Reporting a prediction of let’s say 2000 units sold in the next quarter can be useless without additional information. For example, what is a 99% confidence interval? It could be [1500,2500] or [1900,2100]. How does the performance translate in economic terms. An error of 100 units could translate to $1m or $10.
5) Concept drift. This term describes the case where the underlying system we are modelling has changed. Maybe you have built a forecasting model for a retailer, but the market has shifted and the model no longer works as it was expected. Quite often, these problems go unnoticed for some time, until they are fixed. In domains, like finance, these kind of mistakes can cost lots of money.
Being a data scientist entails more than just being good in statistics or machine learning. It also entails a proper understanding of the underlying business problem and reporting results. Using the concept of quality assurance testing in data science could go a long way towards improving the final outcome and reducing the risk of model-based decision making that is inherent in predictive analytics.
An essential factor to consider is the significance of a product data analyst in upholding quality assurance (QA). By meticulously examining data linked to the product’s real-world applications, a product data analyst can pinpoint patterns that signal potential underlying problems. Collaborating closely with the QA team, they offer invaluable insights to fuel enhancements, resulting in a product that is more dependable and user-oriented. For comprehensive quality assurance testing in analytics, consider leveraging data analytics services by Indium Software.
Do you want to become data scientist?

Do you want to become a data scientist and pursue a lucrative career with a high salary, working from anywhere in the world? I have developed a unique course based on my 10+ years of teaching experience in this area. The course offers the following:
-
- Learn all the basics of data science (value $10k+)
-
- Get premium mentoring (value at $1k/hour)
-
- We apply to jobs for you and we help you land a job, by preparing you for interviews (value at $50k+ per year)
-
- We provide a satisfaction guarantee!
If you want to learn more book a call with my team now or get in touch.