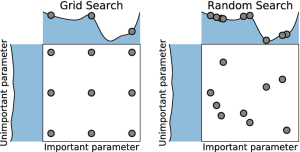
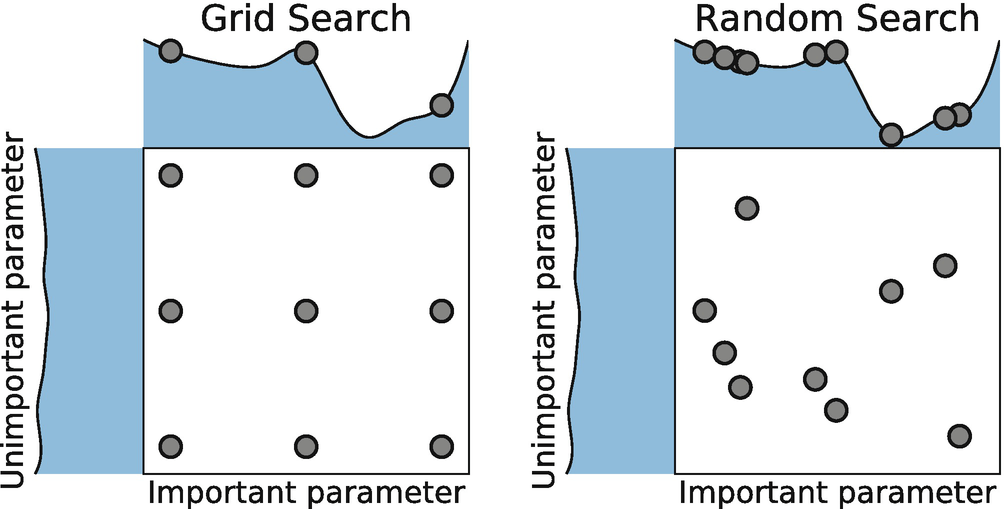
Parameter optimisation is a tough and time consuming problem in machine learning. The right parameters can make or break your model. There are three different ways to optimise parameters:
1) Grid search.
2) Random search
3) Bayesian parameter optimisation
Grid search
Grid search is by far the most primitive parameter optimisation method. When using grid search, we simply split parameter settings unto a grid, and we try out each parameter setting in turn. However, this is not a great strategy for two reasons. First, grid search is very time consuming. Secondly, it doesn’t make much sense to try out parameter settings which are very similar. If, for example, you try to optimise a neural network with a learning rate of 0.001, then switching the learning rate to 0.002 is unlikely to have a serious effect.
Random search
Random search is like grid search but with one important difference. Instead of trying out parameter settings one after another, we are trying out different settings randomly.
In practice this is proven to be a very fast and effective way to find good parameter settings! While it might sound counterintuitive, the reason is simple. Good parameter settings can lie in very different parts of the space we are exploring. Trying out random search helps us quickly explore many different parameter settings to see what works best. It is unlikely to find the global optimum, but it can give us a good starting point. We can then use grid search or bayesian parameter optimisation to find an even better solution.
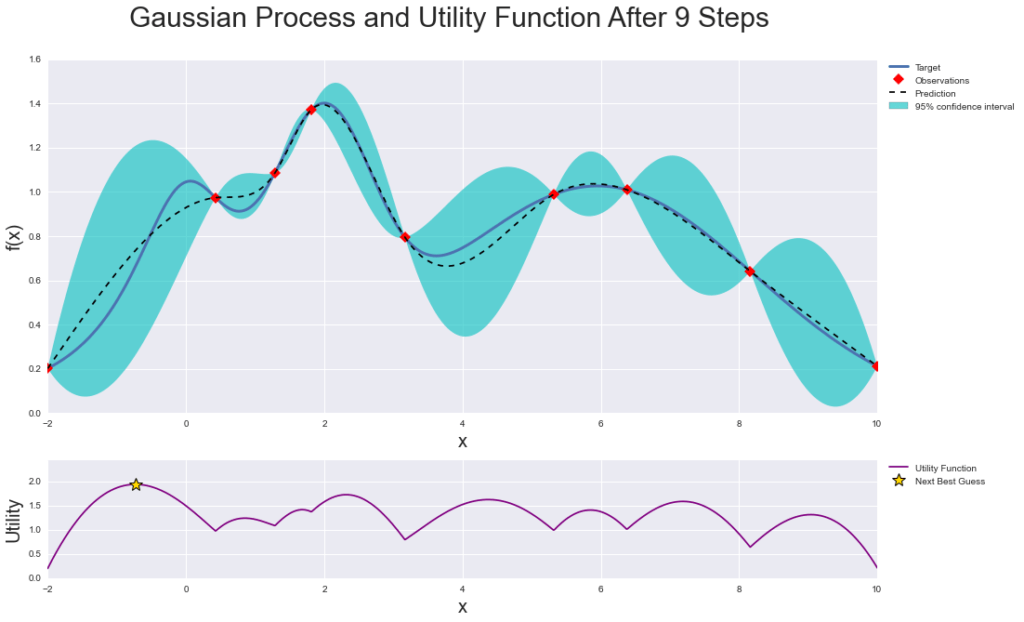
Bayesian hyperparameter optimisation
Bayesian hyperparameter optimisation is the most advanced method. In this case, we are using a machine learning model (like a Gaussian process) in order to predict what a good parameter setting will be. Hyperopt is a good package for this in Python.
A quick and dirty script to optimise parameters for LightGBM
So, I wanted to wrap up this post with a little gift. Below is a piece of code that can help you quickly optimise the LightGBM algorithm. It includes the most significant parameters. I hope you will find it useful!
A few notes:
First, I am using numpy arrays in some cases, in order to restrict the number of options for the sampler.
Secondly, if you try this on your own data, make sure that the number of trees is reasonable for the size of your dataset. Try to have a maximum number of trees that is up to 5x-10x the number of features.
from lightgbm import LGBMRegressor import scipy import numpy as np from sklearn.model_selection import ParameterSampler from sklearn.model_selection import cross_val_score import sklearn from sklearn import datasets import pandas as pd data=sklearn.datasets.load_wine() X=data['data'] y=data['target'] n_estimators=scipy.stats.randint(50,400) max_depth=scipy.stats.randint(2,10) lambda_l1=np.arange(0,0.8,0.05) lambda_l2=np.arange(0,0.8,0.05) extra_trees=[True,False] subsample=np.arange(0.3,1.0,0.05) bagging_freq=scipy.stats.randint(1,100) colsample_bytree=np.arange(0.3,1.0,0.05) num_leaves=scipy.stats.randint(10,100) boosting=['gbdt','dart'] drop_rate=np.arange(0.1,0.8,0.1) skip_drop=np.arange(0,0.7,0.1) learning_rate=[0.00001,0.0001,0.001,0.01,0.015,0.02,0.05,0.1,0.15,0.2] params = {'n_estimators':n_estimators,'max_depth':max_depth, 'subsample':subsample, 'colsample_bytree':colsample_bytree, 'learning_rate':learning_rate, 'num_leaves':num_leaves, 'boosting':boosting, 'extra_trees':extra_trees, 'lambda_l1':lambda_l1, 'lambda_l2':lambda_l2, 'bagging_freq':bagging_freq, 'drop_rate':drop_rate} params = list(ParameterSampler(params, n_iter=2000)) store=[] for i in range(len(params)): print(i) p=params[i] model=LGBMRegressor(**p,objective='rmse') score=cross_val_score(model,X,y,cv=10) store.append({'parameters':p,'r2':score}) print(score) store=pd.DataFrame(store)
Do you want to become data scientist?

Do you want to become a data scientist and pursue a lucrative career with a high salary, working from anywhere in the world? I have developed a unique course based on my 10+ years of teaching experience in this area. The course offers the following:
- Learn all the basics of data science (value $10k+)
- Get premium mentoring (value at $1k/hour)
- We apply to jobs for you and we help you land a job, by preparing you for interviews (value at $50k+ per year)
- We provide a satisfaction guarantee!
If you want to learn more book a call with my team now or get in touch.