The differences between machine learning and statistics
Machine learning and statistics are the two core disciplines for data analysis. Both fields provide the scientific background for data science and data scientists will usually have trained in one of the two. However, much has been said about the differences between the two disciplines, while there are proponents only of one approach. So, what are the differences?
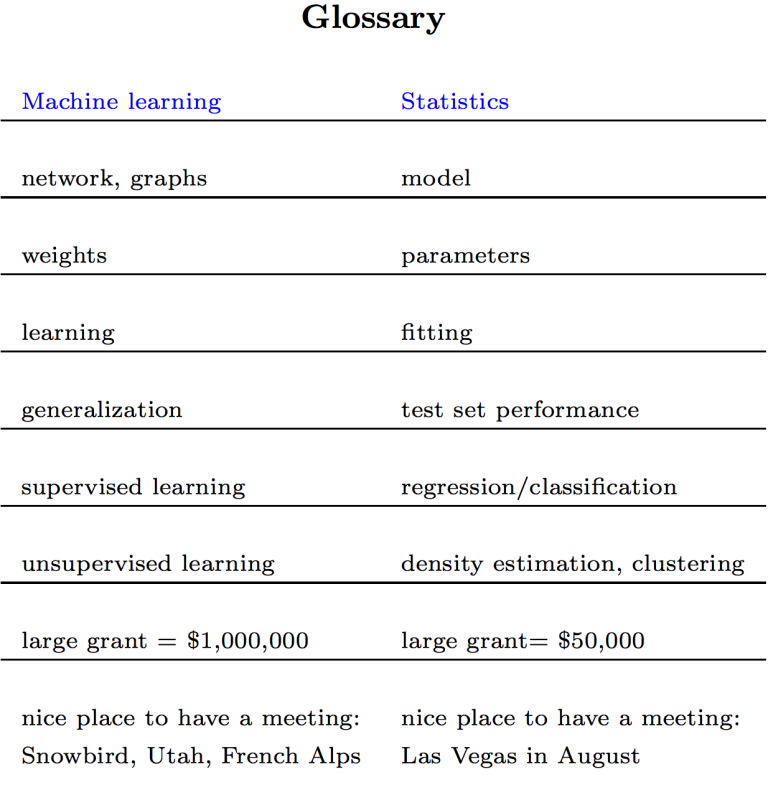
Well, there are two main differences. The first one, which is not very important, is terminology. A very good comparison by the excellent statistician — and machine learning expert —Robert Tibshiriani is reproduced here:
The second difference, which is fundamental, is that machine learning is focused on prediction while statistics is focused on mathematical modelling. Also, machine learning is influenced a lot by the “engineering” mentality which exists in computer science departments. It’s more important to make something work, even if there is not a clear theory behind it.

Two different views on data science
So, in machine learning you have algorithms such as neural networks that can identify non-linear patterns and interactions in the data. In statistics, on the other hand, you have significance testing for assessing the important of each individual variable.
Probably, no-one said it better than Leo Breiman, the inventor of random forests, one of the most successful algorithms in data science (link to paper here):
“There are two cultures in the use of statistical modeling to reach conclusions from data. One assumes that the data are generated by a given stochastic data model. The other uses algorithmic models and treats the data mechanism as unknown. The statistical community has been committed to the almost exclusive use of data models. This commitment has led to irrelevant theory, questionable conclusions, and has kept statisticians from working on a large range of interesting current problems. Algorithmic modeling, both in theory and practice, has developed rapidly in fields outside statistics. It can be used both on large complex data sets and as a more accurate and informative alternative to data modeling on smaller data sets. If our goal as a field is to use data to solve problems, then we need to move away from exclusive dependence on data models and adopt a more diverse set of tools.”

Note that Breiman was more in favour of the “machine learning” way of thinking (as you probably guessed from the abstract).
Machine learning might be getting more credit nowadays than statistics, mainly because the abundance in data makes it easy to build successful predictive models. Statistics shines more when the data is limited and when we care about specific hypotheses.
These differences can also be attributed to the history of the fields. Modern statistics came about the 19th century when data was sparse, so creating models with strong assumptions could counteract the absence of data, if these assumptions were correct. When there is a huge amount of data, however, you can get pretty good solutions with non-parametric methods or other types of approaches. SVMs for example take a geometric view on learning which does not include any probabilistic thinking at all.
My personal approach is to take the best of both worlds and to use the right tool for the job. The term data science will hopefully move towards a greater integration of both fields.
The Wikipedia defines data science as a field that “incorporates varying elements and builds on techniques and theories from many fields, including math, statistics, data engineering, pattern recognition and learning, advanced computing, visualization, uncertainty modeling, data warehousing, and high performance computing with the goal of extracting meaning from data and creating data products.”
So, just be aware of the differences between the fields and use what’s best for your problem at hand! If you’d like to learn more about the subject and similar topics, such as the difference between AI and ML, then check out some of my courses, or the Tesseract Academy.
[sc_fs_faq sc_id=”fs_faqfxkunkgj6″ html=”true” headline=”h3″ img=”” question=”So, in short, what is the difference between machine learning and statistics?” img_alt=”” css_class=”” ]In a few words the main difference is on the focus that each approach has. Statistics is focused more on interpretability, whereas machine learning is focused more on prediction. The right approach depends on your particular problem.[/sc_fs_faq]
Some extra reading:
History of statistics on Wikipedia
A nice post from Win-Vector: The differing perspectives of statistics and machine learning
An interesting view by Brendan O’Connor: Statistics vs. Machine Learning, fight!