
Solving machine learning problems can be complicated, especially if you’re new to the field. That’s why we’ve created this guide to help you through the process, from deciding which problem to solve to choosing the right tools to do it with and how to validate your results to ensure they’re accurate. With this guide, you’ll be able to solve any machine-learning problem quickly and easily, regardless of your background.
Why is it Difficult to Solve Machine Learning Problems?
Machine learning problems can be complex and perplexing, but there are several steps you can take to make the solution process easier and faster. Taking the time to plan out your approach to solving these problems will save you time and frustration in the long run, so take your time with this write-up that shows you how to solve machine-learning problems quickly and easily.
How to Solve Machine Learning Problems Quickly and Easily
To solve machine learning problems, you need to know how to devise an effective strategy. The one you will use for making your algorithm as accurate as possible. You can use many algorithms, such as logistic regression, decision trees, and neural networks. All these require an answer to the same question. What data do I need to find the best solution? All that will give you the necessary answers, so you’re not stuck. And agonizing over your data or code when it comes time to make your algorithm accurate.
Understand the Problem

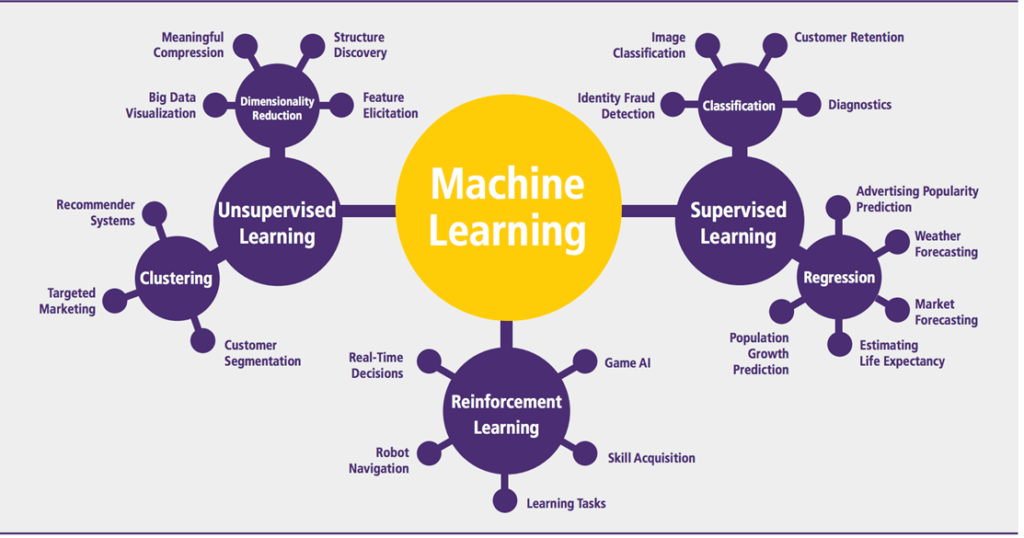
Machine learning is a subset of artificial intelligence that enables computers to learn and improve from experience without deep programming. It’s the core technology behind everything from Siri, Google Translate, Facebook’s News Feed, self-driving cars, etc. Also, many other applications depend on data analysis.
There are many ways to solve machine learning problems – depending on the problem. For example:
If you need your program to predict something with high accuracy, but there is a limited amount of training data available, you might use an algorithm such as Random Forest or K Nearest Neighbors.
Choose the Right Model
The first step is to figure out which model to use, which is often the most challenging part. There are many different models with different strengths and weaknesses, so you must choose the right one for your problem. Here are a few considerations that can help you make a decision:
How much detail of your data is in the system? Some models might be better for simple datasets than others. However, you can do it in the same pattern as developing various small business packaging ideas. To put it differently, it is easier than it sounds.
Does your data have multiple features or just one? If it has only one feature, then linear regression or logistic regression might be best for you. But if you want to analyze two or more features simultaneously, then a tree-based model like a random forest might work well.
Train the Model
The training process involves feeding data into the machine learning algorithm to learn patterns in the data. You then use this knowledge to predict new values or categories.
- You need input data (i.e., your training set) to train your model. An excellent first step is separating your input into two parts: a training set and a validation set.
- The validation set will be later during testing, while the training set is what the algorithm uses to input learning patterns in your data.
- During the training phase, we are telling the model which inputs are numerous positive examples (also known as y) and which are not.
- We label these types of inputs for target output or not for non-target output.
- For instance, if we wanted to teach our neural network that pictures with green leaves would always have lots of cats, we would show it lots of pictures with green leaves and say that those pictures without any cats would be labeled.
By repeating this process repeatedly with different sets of pictures from both groups, our neural network should eventually develop its generalizable rule – that when there are green leaves in a picture, there are usually cats around too!
Evaluate the Model
The most crucial part of solving a machine learning problem is figuring out the model that you will use to solve it. After you’ve determined what model will work, you can evaluate it by looking at how well it solves your problem.
The three main types of models are:
The ones you supervise, not supervise, and semi-supervise.
Of course, there are some other models, but we’ll focus on these three. Once you know which type of model is appropriate, you need to figure out whether the data set you’re using is labeled or unlabeled data. For example, in a strict model, the training data (or labeled) gets into the algorithm to learn from those examples.
Afterward, during testing (or evaluation), new inputs from data are in the algorithm to determine its accuracy. For example: If someone has diabetes and their blood sugar level is constantly above 200 mg/ld., they would have an insulin dose label that would let you know if they needed more insulin.
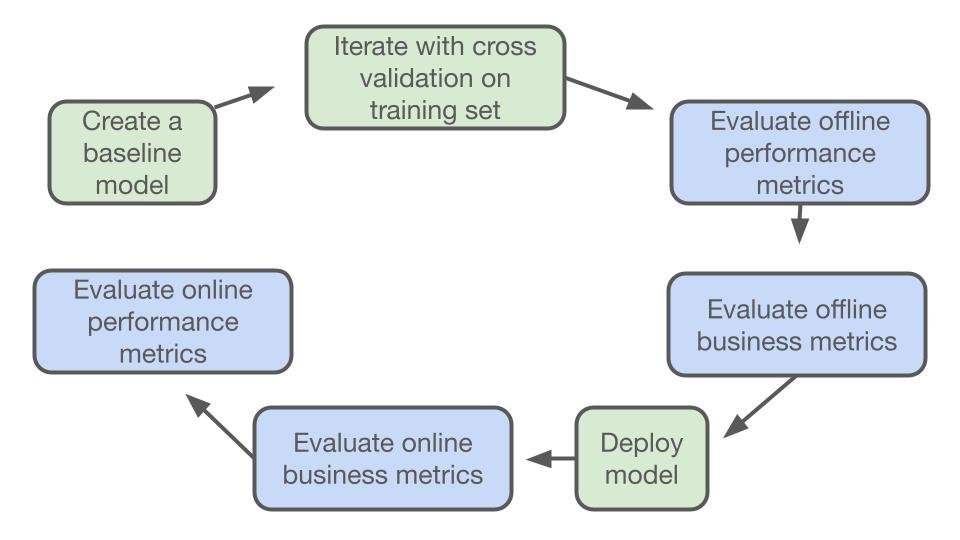
Tune the Model
The first step in solving a machine-learning problem is tuning the model. This means finding the right set of parameters for the data you want to analyze. Therefore, the first thing you should do is find a hyperparameter search tool that suits your needs. For instance, if you are working on the trends of the ecommerce industry, you will have to search for a tool according to it.
One example of this type of software is Hyperopt. Once you select an appropriate hyperparameter search tool, all that’s left to do is input your data, select your algorithm, and click search. If there are too many results to review, you can use some criteria to narrow your search.
For instance, if you’re looking for parameters that will work with classification algorithms, you can use cross-validation error or AUC as your metric. On the other hand, if it only helps a little with narrowing down the results, then go with the Bayesian information criterion (BIC).
Which Processes Need Machine Automation More
The processes that need machine automation the most are those that humans have historically done but take a lot of time to complete. For example, if you’re in the banking industry, you might have an employee manually search for every account with a balance below $10,000. A machine could perform this task quickly, without error, and without allocating any time or resources from your human employees. With machine automation, you can free up your people for more important tasks that require their skill sets.
Automating repetitive tasks is the first step to achieving machine automation. This will save your employees time on mundane tasks and allow them to focus their energy on more important assignments.
Take Care of Inadequate Infrastructure
Choosing the best one for your problem can take much work with many frameworks. The easiest way is to use a library that does all the heavy lifting for you. For example, if you want to solve a machine learning problem quickly and easily, use Scikit-learn.
For other tasks like image recognition or machine translation, try Caffe or Google Translate API, respectively. When choosing the suitable model from among the choices of linear regression, support vector machines (SVM), decision trees, etc., keep in mind what type of data you have: text input data or images with pixel values.
It would help if you also considered how much time you have available on hand. If time is not an issue and accuracy is essential, go with SVM; otherwise, start with something simple such as linear regression.
Overcome Your Lack of Skilled Resources
As machine learning becomes more prevalent, companies need more skilled resources to solve specific machine-learning problems. This can be especially true for small or mid-sized companies needing a dedicated data scientist.
To overcome this lack of skilled resources, it is essential to make sure that you are taking advantage of all the free tools out there that can help you solve your machine-learning problems quickly and easily.
For example, Google’s TensorFlow is an open-source software library for numerical computation using data flow graphs created by Google employees during their research into deep neural networks.
It solves many computer science problems related to machine intelligence, such as speech recognition, image recognition, natural language processing (NLP), reinforcement learning, etc.
Final Verdict
Machine learning is an exciting field with a lot of opportunities for innovation. But no matter how excited you are, tackling machine learning problems can take time and effort. You need to know so many things before you can even start. But that’s not the case! Our blog posts will walk you through how to solve machine-learning problems quickly and easily.

If you want to learn more about data science or become a data scientist, make sure to get in touch. Also, make sure to check out our data science bootcamp Beyond Machine. We are the only program in the market that helps you find a job in data science, and even makes job applications for you!