
These models are designed to generate new data that resembles the training data, and they come in many forms, each serving different purposes. This article explores the five main types of AI generative models, highlighting both open-source and paid options, where to access their APIs, and their most common uses.
1. Text Generation AI Models
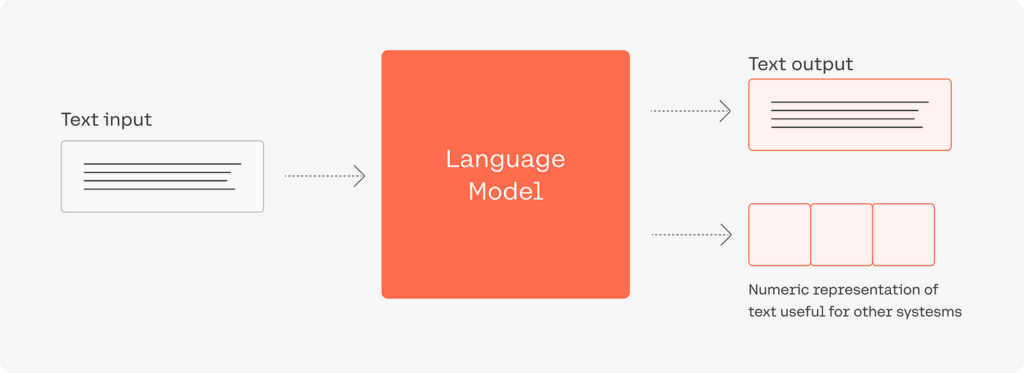
Overview: Text generation models are AI systems trained to produce text. They can write articles, compose poetry, generate code, and even create conversational responses. These models learn from a large corpus of text to generate new text that’s similar in style and content.
Open Source Options: GPT-2 by OpenAI is a prominent open-source option, offering powerful text generation capabilities. BERT and T5 are other examples, widely used for their versatility in text understanding and generation tasks.
Paid Options: GPT-3, also by OpenAI, represents the leading edge in text generation, available through a paid API. It’s known for its ability to generate highly coherent and contextually relevant text across a wide range of topics and styles.
API Access: OpenAI provides access to GPT-3 through its API platform (api.openai.com), requiring a subscription for usage. GPT-2 and other open-source models can be accessed via Deep Infra’s library, which offers an easy way to implement these models in various applications.
Common Uses: These models are commonly used for content creation, chatbots, language translation, and automated customer service responses.
2. Text to Image AI Models
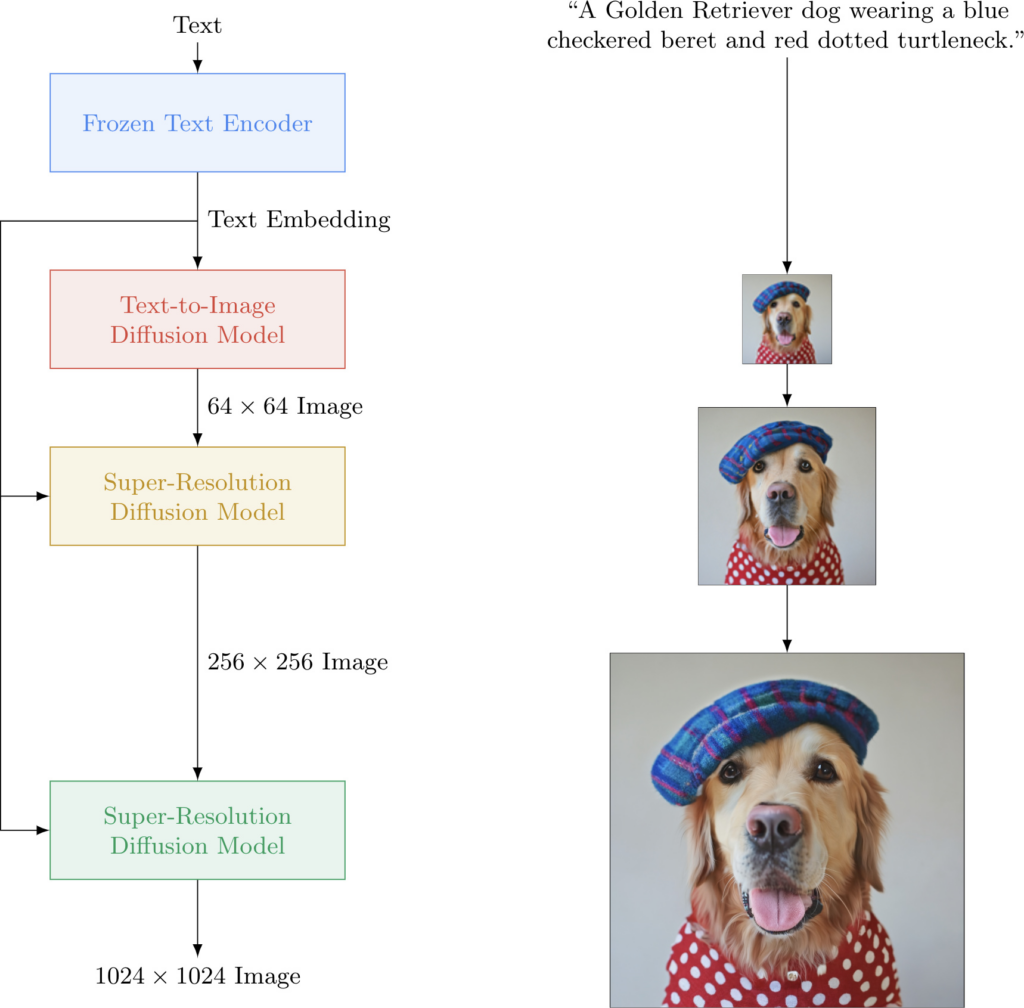
Overview: Text to image models generate visual images from textual descriptions, enabling the creation of artwork, product prototypes, and visual concepts directly from text inputs.
Open Source Options: VQ-VAE-2 and DALL-E mini are accessible open-source models that offer decent capabilities for generating images from text descriptions.
Paid Options: DALL·E 2 by OpenAI is a state-of-the-art model offering high-quality, coherent images based on textual descriptions, available through a paid API.
API Access: OpenAI’s DALL·E 2 API (api.openai.com) provides access to their text-to-image model, while open-source models like DALL-E mini can be found on platforms like Deep Infra and GitHub.
Common Uses: These models are used in creative industries for generating artwork, advertising material, and concept art, as well as in product design for visualizing new ideas.
3. Speech Recognition Models
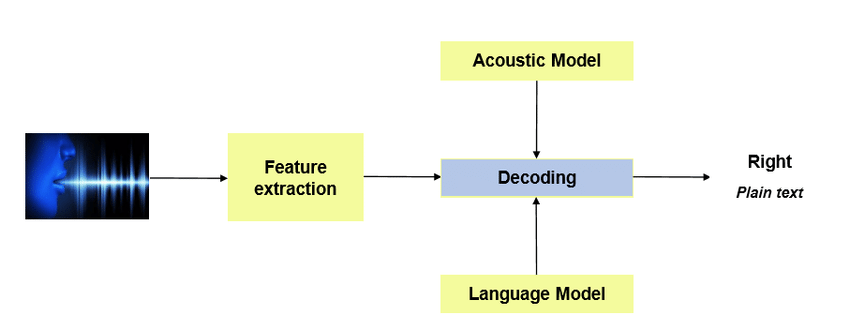
Overview: Speech recognition models convert spoken language into text, enabling voice-controlled applications, dictation, and automated transcription services.
Open Source Options: Mozilla’s DeepSpeech is a popular open-source speech recognition model, offering a solid foundation for building speech-to-text applications.
Paid Options: Google Cloud Speech-to-Text and Amazon Transcribe provide highly accurate speech recognition services through their paid APIs, supporting multiple languages and dialects.
API Access: Google Cloud Speech-to-Text (cloud.google.com/speech-to-text) and Amazon Transcribe (aws.amazon.com/transcribe) offer cloud-based APIs. Mozilla’s DeepSpeech can be accessed through its GitHub repository.
Common Uses: Used in voice-activated assistants, real-time transcription services, customer service automation, and language learning tools.
4. Object Detection Models
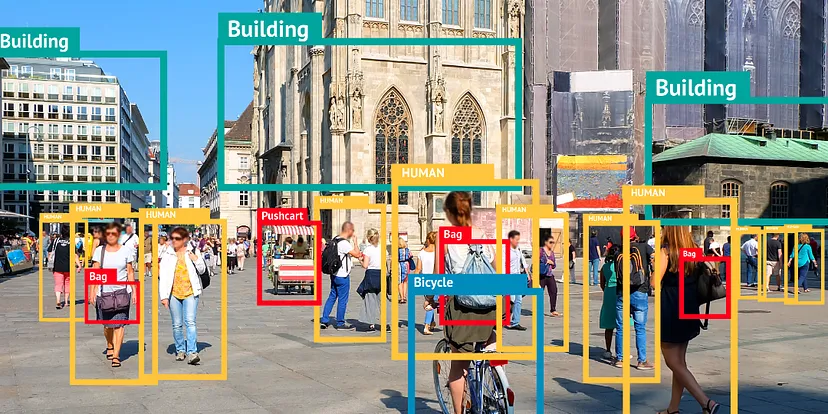
Overview: Object detection models identify and locate objects within images or videos, useful for surveillance, quality control, and augmented reality.
Open Source Options: YOLO (You Only Look Once) and Faster R-CNN are widely used open-source models for real-time object detection.
Paid Options: Google Cloud Vision API and Amazon Rekognition offer object detection capabilities as part of their broader suite of vision AI services, available through paid APIs.
API Access: Access to Google Cloud Vision API and Amazon Rekognition can be found on their respective websites (cloud.google.com/vision and aws.amazon.com/rekognition). YOLO and Faster R-CNN can be implemented via GitHub repositories.
Common Uses: These models are applied in security and surveillance systems, automated inspection in manufacturing, and interactive retail experiences.
5. Image Classification Models
Overview: Image classification models categorize images into predefined classes, essential for organizing large datasets, content filtering, and diagnostic assistance.
Open Source Options: ResNet and Inception are two leading open-source models known for their accuracy in image classification tasks.
Paid Options: Clarifai and IBM Watson Visual Recognition offer advanced image classification services, including custom model training, through their paid APIs.
API Access: Clarifai (clarifai.com) and IBM Watson Visual Recognition (ibm.com/watson/services/visual-recognition) provide API access to their platforms. Open-source models like ResNet and Inception can be accessed through TensorFlow or PyTorch libraries.
Common Uses: Used in digital asset management, content moderation, medical imaging analysis, and automatic tagging of images on social platforms.
Common Questions About AI Model Types
Text Generation AI Models
Q1: How do developers integrate text generation models into applications?
A1: Developers can integrate text generation models like GPT-2 or GPT-3 using APIs or libraries such as Hugging Face’s Transformers. For GPT-3, developers must use the OpenAI API, requiring authentication, API keys, and adherence to rate limits. For open-source models, developers can directly download the pre-trained models and use libraries like TensorFlow or PyTorch for integration, handling input preprocessing and output postprocessing as needed.
Q2: What are the main challenges in training custom text generation models?
A2: Challenges include the need for large, diverse datasets to avoid biases, significant computational resources for training, managing overfitting to maintain generality of the generated text, and ethical considerations to prevent the generation of harmful content. Developers must also fine-tune models on domain-specific data to achieve high-quality outputs.
Q3: How do sequence length and context size impact text generation quality?
A3: The sequence length and context size directly impact the coherence and relevance of the generated text. Larger context sizes allow models to maintain context over longer texts, improving consistency and relevance. However, they require more memory and computational power. Optimizing these parameters is crucial for balancing performance and resource usage.
Q4: Can text generation models handle multiple languages?
A4: Yes, multi-lingual models like mBERT and GPT-3 have been trained on datasets comprising multiple languages, enabling them to generate text in various languages. However, the quality of generation can vary based on the representation and diversity of the language in the training dataset. Fine-tuning with language-specific data can improve performance.
Q5: What are the best practices for deploying text generation models in production?
A5: Best practices include implementing rate limiting and monitoring to manage API usage and costs, using caching strategies for frequently requested outputs, ensuring data privacy and security compliance, and actively monitoring the model’s outputs for biases or inappropriate content to maintain ethical standards.

Text to Image AI Models
Q1: What technical considerations are important when working with text-to-image models?
A1: Key considerations include understanding the model’s input requirements (e.g., text prompt limitations), managing computational resource needs (as image generation can be resource-intensive), handling variability in output quality, and incorporating user feedback loops for iterative refinement of generated images.
Q2: How can developers customize text-to-image models for specific domains?
A2: Customization can be achieved through fine-tuning pre-trained models with domain-specific datasets. This involves retraining the model on a curated dataset of text-image pairs relevant to the target domain, adjusting model parameters to optimize performance for the specific type of images or descriptions.
Q3: What frameworks support the implementation of text-to-image models?
A3: Frameworks like PyTorch and TensorFlow are commonly used to implement text-to-image models. They provide the necessary libraries for model training, optimization, and deployment, along with support for GPU acceleration which is crucial for the computationally intensive process of image generation.
Q4: Are there scalability challenges with deploying text-to-image models?
A4: Yes, text-to-image models, especially sophisticated ones like DALL·E 2, require substantial computational resources for inference. Scalability challenges include managing the load on servers, optimizing response times, and controlling costs. Solutions include using cloud-based GPUs, optimizing model architecture for efficiency, and implementing queuing systems for managing requests.
Q5: How do developers ensure the ethical use of text-to-image models?
A5: Ensuring ethical use involves implementing filters to prevent the generation of inappropriate or harmful content, respecting copyright and intellectual property laws, and considering the impact of generated images on societal norms and values. Developers should also provide users with guidelines on responsible use and actively monitor and update models to address ethical concerns.
Speech Recognition Models
Q1: What are the key factors affecting the accuracy of speech recognition models?
A1: Accuracy is influenced by the model’s architecture, the diversity and quality of the training data (covering various languages, accents, and environmental conditions), and the model’s ability to handle background noise and distinguish between similar-sounding words. Fine-tuning with domain-specific audio can improve accuracy in targeted applications.
Q2: How do developers optimize speech recognition models for real-time applications?
A2: Optimizations include reducing model complexity, implementing efficient neural network architectures (e.g., using convolutional layers for feature extraction), leveraging hardware acceleration (GPUs, TPUs), and optimizing the audio preprocessing pipeline to reduce latency.
Q3: What are the challenges in deploying multilingual speech recognition models?
A3: Challenges include collecting and annotating a diverse dataset that accurately represents the linguistic nuances of each language, managing the increased model complexity and resource requirements, and ensuring the model performs equally well across all languages. Techniques like transfer learning and multi-task learning can help address these challenges.
Q4: Can open-source speech recognition models compete with commercial offerings?
A4: Open-source models like Mozilla’s DeepSpeech offer competitive performance and flexibility, especially for developers looking to customize or extend the models for specific use cases. However, commercial offerings may provide higher accuracy, broader language support, and additional features like voice activity detection, making them more suitable for certain applications.
Q5: What considerations should be made for privacy and security in speech recognition applications?
A5: Privacy considerations include ensuring that voice data is encrypted in transit and at rest, obtaining user consent for data collection and processing, and implementing access controls and audit logs. Security considerations involve protecting the speech recognition system from malicious inputs and ensuring that the system does not inadvertently expose sensitive information contained in the transcribed text.

>>>>>>>>>>>>>>>>>>>>>>>>>>>>>