Deep learning against humans
Creating machines that can perform tasks better than humans has always been the dream behind artificial intelligence. A London-based company called DeepMind, had a breakthrough in 2015, when it produced a deep neural network, called AlphaGo, that can beat a professional Go player. This was the first time a computer program does that.
DeepMind first became a sensation when they trained deep neural nets to beat video games. This idea was exceptionally good for the reason that it allowed AI to interact and receive feedback in a world without noise. This simple, but powerful idea, was crucial to DeepMind’s success. Most researchers believed that true general intelligence would have something to do with interaction with the real world. This is something that is also depicted in popular science fiction, where you have robots like the Terminator, or self-driving cars like Knight Rider.

At that point, most researchers jump to the conclusion that general artificial intelligence must have something to do with robotics. However, as most people in robotics will tell you, in that field you spend the majority of the time trying to make the hardware work and clear out the noisy signals received from sensors. This adds two more levels of complexity to a problem that is already very difficult.
Video games provide an ideal simulation of the real world. They use simplified versions of real world physics and interactions. Also, there are video games with various gradients of complexity, from simple ones (e.g. 2d games such as pac-man) to very complicated ones (e.g. 3D first-person RPGs such as Fallout). This allows the training and testing of AI programs under simpler, but similar conditions, to the real world.
This idea was hugely successful. They tested it on 49 games and the deep neural nets managed to learn how to play the majority of them, even achieving human performance on a few games. The original paper can be found here: Human-level control through deep reinforcement learning. The latest attempt has taught a deep neural network how to navigate a 3D area similar to the ones found in the video game Doom.

Teaching a deep neural network to play go
Beating a professional at Go is a huge achievement, given that Go is far more complicated than chess and no system had ever succeeded in beating a professional human player. The approach they followed is very interesting, because it combines many different concepts.
Trying to solve Go using brute force results very fast in combinatorial explosion. A technique that has become very popular in the last few years is Monte Carlo Tree Search (MCTS). MCTS is basically a way to randomly sample from the tree of possible moves in order to find the most promising ones.
Tree search is one of the cornerstones of classic AI. Classic AI was largely based on rules and logic, in contrast to today’s machine learning that is mostly based on probabilities and approximate inference. Classic AI failed for various reasons, two of which were the following. First, because it couldn’t handle uncertainty very well. Uncertainty is in many real systems, from the noise of sensors, to the outcome of a particular action. Secondly, because combinatorial explosion can become a real problem, too fast, in many applications.

In this particular case, MCTS can improve the problem of creating a program that plays Go, by using sampling in order to heuristically find good moves. DeepMind enhanced this technique by using deep neural nets that learned how to play Go based on a database of movements from experts and self-play.
AlphaGo contains two deep neural networks that learn from a vast database of moves (more than 30 million) made by experts in Go. The first network (called rollout policy network) is not very accurate (24.2%), but it is fast in execution time (2 microseconds per evaluation), which makes it highly practical later down the line. The other network (called supervised learning or SL policy network) is much more accurate with 57.0% accuracy, but much slower (3 milliseconds per evaluation).
The second deep neural network’s weights (the most accurate) is then used in order to initialize a reinforcement learning network which then trains its weights by playing games against itself. This is a technique that had been used in the past in backgammon and was one of the first successes of reinforcement learning.
This is what happens in simple words. The network at its initial state, has the weights of the supervised learning network. So, it can play by simply mimicking the way that experts would play, since the original SL policy network was trained by predicting expert moves. Playing against itself makes it improve on its strategy, possibly by reaching a super-human level of performance (read about TD-Gammon if you want to know why this works). The only way to become better at a game is by playing against an equal or stronger opponent.
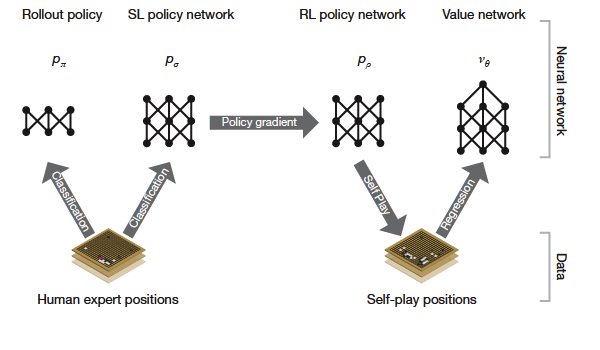
In the next step a new deep neural network is created that learns from the games of the RL network against itself. This is called the “value network“, and produces a value score for each movement. The value network can produce Monte Carlo rollouts similar to accuracy to the RL policy network but 15000 times faster.
Finally, the value network and the rollout policy network are used together in order to evaluate the moves searched through MCTS. The reason to use this network instead of the SL policy network is that it is much faster. So, the final evaluation function is a combination of a network that is mimicking human expert moves (the rollout policy network) and a network that has learned from an expert neural network (the value network).
deep neural networks against human players
So, to recap this is what is happening in brief:
- Learn how an expert would play through a vast database of human expert moves.
- Improve upon this concept by making a deep neural network play against itself.
- Create another network to learn how valuable a move is by using data from the games of the last network against itself.
- Use this network, alongside the rollout policy network, in order to value moves through MCTS.
What is particularly interesting in this paper is that we see neural networks being used in different ways and techniques borrowed from AI being merged with more recent approaches. Supervised learning is used in order to learn from a dataset of expert moves, then reinforcement learning is used in order to improve game-playing and finally this is used in a more formal tree search algorithm, reminiscent of classic AI.
We live in very exciting times in AI research, and only time will tell how far we can go. If you also want to learn more about the subject make sure to check my video below about the different types of neural networks.