
Creating data products is not easy
I was reading recently a very interesting article on O’Reilly’s blog: Designing great data products. I thought it would be good to summarise it and add some of my own thoughts, since it touches upon some of the themes that I am also covering in my work.
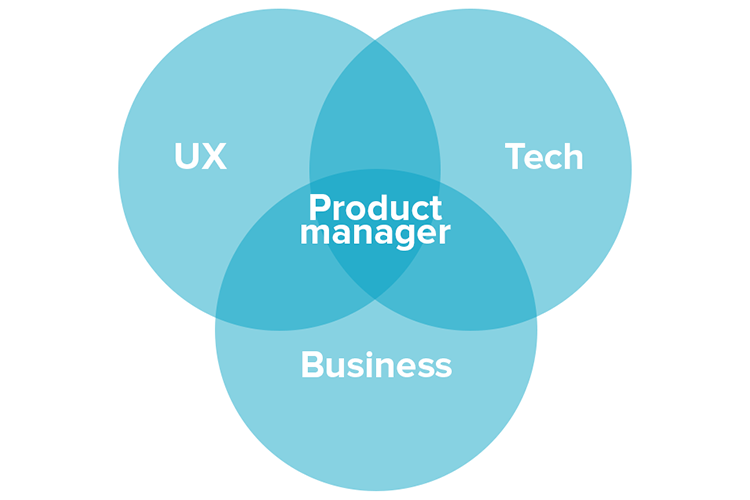
The blog discusses the issue of using data science to create products. One of the main issues in the design of data products, is that data scientists, quite often, do not have good business understanding. At the same time, people responsible for coming up with the products, e.g. product managers, might not be very familiar with the possibilities and limitations of machine learning.

This can not only cause a bottleneck, but it can also be a way to lose time and resources by chasing the wrong things. For example, many times data scientists might focus on projects with no relevant business application. Or a product manager might try to create a product around a predictive model, which is impossible to make it work (e.g. because the data might not be right).
Data products, data roles and processes
For this reason, there are many solutions that have been proposed from time to time. One such solution, is to create new roles. For example, I have proposed in the past that a new role could be created: the data science architect. Other people have talked about the role of a data science product manager. That is a product manager with some understanding of data science, or the opposite (a data science with some understanding of product).
The solution that Jeremy Howard, Margit Zwemer and Mike Loukides outlined in their article on O’Reilly’s blog is to the drivetrain process. I find their view very interesting, because I am a big fan of processes. If you go to the Tesseract Academy‘s webpage, on the tools section, you will find some useful ones, like the Data Science Project Assessment Questionnaire and the DS10 Questionnaire.
These kinds of tools help you put a project into perspective. Furthermore, they can help a manager really own the project, and understand the risks associated with it, and how to deal with them. So, the drivetrain approach is one such process/tool. So, what is it about?
The drivetrain approach
The drivetrain approach is broken down into the following simple steps
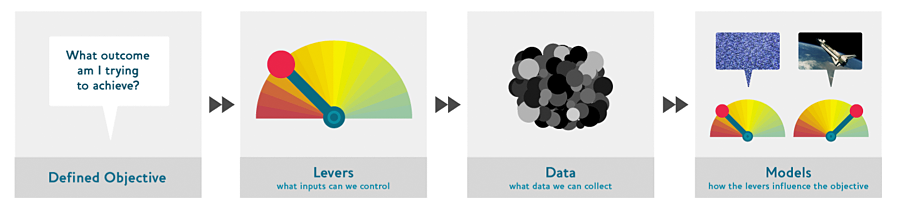
- Define an objective
- Understand the levers: what inputs can you control?
- What data can you collect?
- Model the levers in order to understand how they affect the objective.
The final step, which is not shown in the picture, is to optimise the model, in order to understand what is the best way to affect the levers. The process is really simple, and it has many commonalities with a process I have talked about in the past: the predict-and-optimise framework. The authors of the drivetrain approach call this the “model assembly line”.
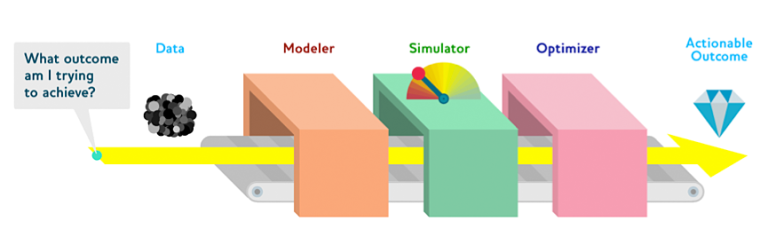
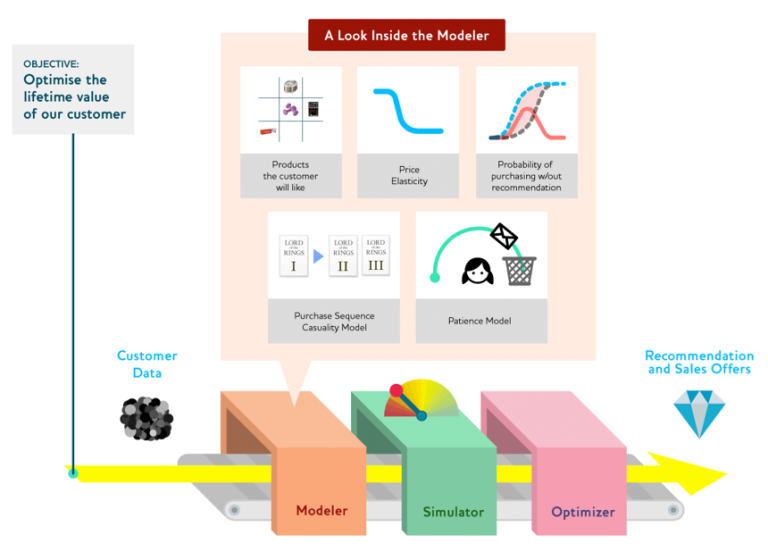
So, for example, let’s say that you want to use this approach to build a recommender system. The first thing you want to do is to define the objective. Do you want to improve sales? Customer retention? Serendipity? What exactly? In the example in the article, the authors define the objective as
“The objective of a recommendation engine is to drive additional sales by surprising and delighting the customer with books he or she would not have purchased without the recommendation.”
This is a very good objective. The lever that you can control, is the ranking of the recommendations. Regarding the data, you have access to the user’s information, and what they’ve looked in the past. However, we have to look into other matters as well.
For example, not all customers share the same price elasticity. Also, some customers might be annoyed if the recommendations are highly irrelevant. Finally, we want to make sure that we are recommending items that the users were not going to buy anyway. Otherwise, we are recommending the obvious.
All these goals can be added into the mix of the modeller, and then we optimise the levers in order to get recommendations that can satisfy all of them.
So, is the drivetrain approach good?
I think that the drivetrain approach is a good way to think about problems in data science, and how you can translate those into products that have business impact. It is similar to the predict-and-optimise framework I’ve discussed in the past.
My opinion is that, while this process is useful, the most important thing is that a company has a process in the first place. There are many factors that involved in a data science project, and the fact that there are also, usually, different specialisms and departments involved, make things even more complicated. A single data product might need the development team, the data science team, product managers, and a direct line of communication with upper management.
A process can help keep everyone on the same track, or at least communicate so that everyone is on the same page. This might sound simple and basic, but it’s really not. Usually, different departments have different assumptions about how things should be done, and quite often, this can lead to disaster.
The drivetrain approach, or the PAO framework or something like CRISP-DM can help companies better understand how data science projects and data products should be structured. So, it is highly recommended that you find a process that works for you, and try to apply it.