What: This article explores the details of Tree-based models. It provides a detailed explanation of its types, pros and cons, and their use and implementation.
Why: This article is a must-read for a beginner trying to understand tree-based models or a proficient learner looking to master its applications in machine learning for enhanced interpretability and nonlinear problem-solving.
What Are Tree-based Models?
Tree-based models are machine learning algorithms. It makes predictions by organizing data into a tree structure. In tree-based models, a set of splitting rules actively partitions the feature space into multiple smaller, non-overlapping regions with similar response values.
Tree-based models are a popular approach in machine learning due to several benefits. They are a category of machine learning algorithms that utilize decision trees as their fundamental building blocks.
Types Of Tree-based Models
Let’s discuss the types of tree-based models in detail:
- Decision Trees
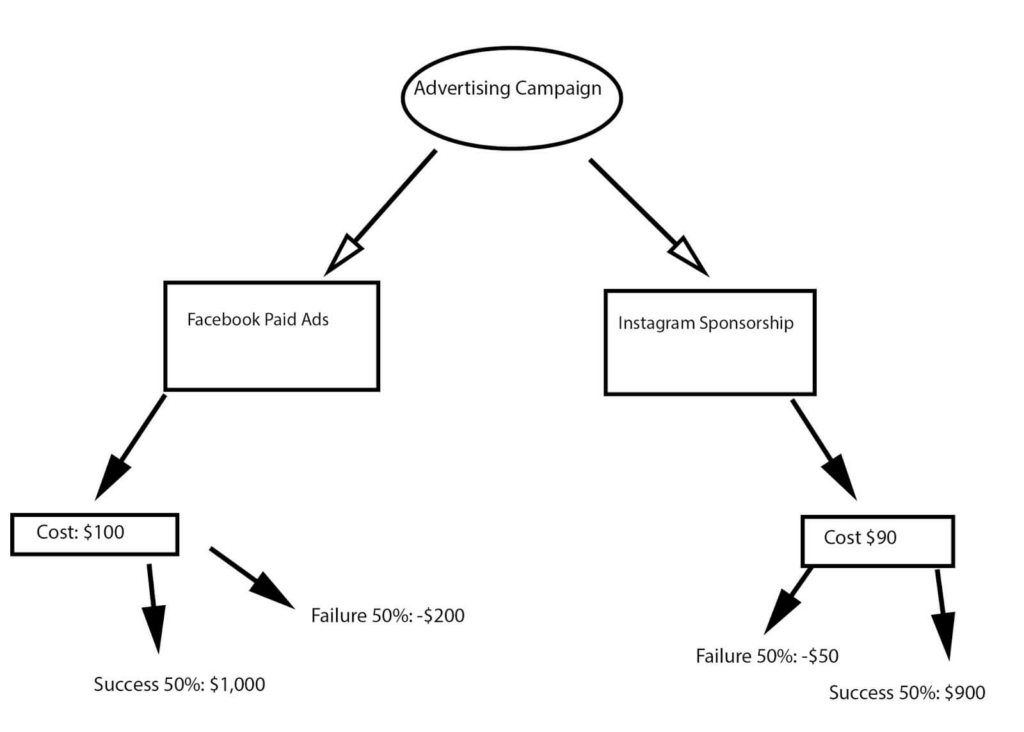
Decision trees are a non-parametric supervised learning method used for regression and classification. It works like an if-else statement.
This is a go-to model for easy interpretation. We can easily follow the steps taken by the decision tree.
Also, it requires little to no data preparation and feature scaling. Decision trees can solve both classification and regression tasks.
- How To Create A Decision Tree?
To create a decision tree, follow these steps;
1. Define your main idea or question.
2. Add potential decisions and outcomes.
3. Expand until you hit endpoints.
4. Calculate risk and reward.
5. Evaluate outcomes.
- Advantages And Disadvantages Of Decision Tree
Here are some of the advantages and disadvantages of the decision tree:
Advantages:
- Interpretability
- No Need for Data Normalization
- Handles Both Numerical and Categorical Data
- Automatic Variable Selection
Disadvantages:
- Overfitting
- Instability
- Biased Toward Dominant Classes
- Limited Expressiveness
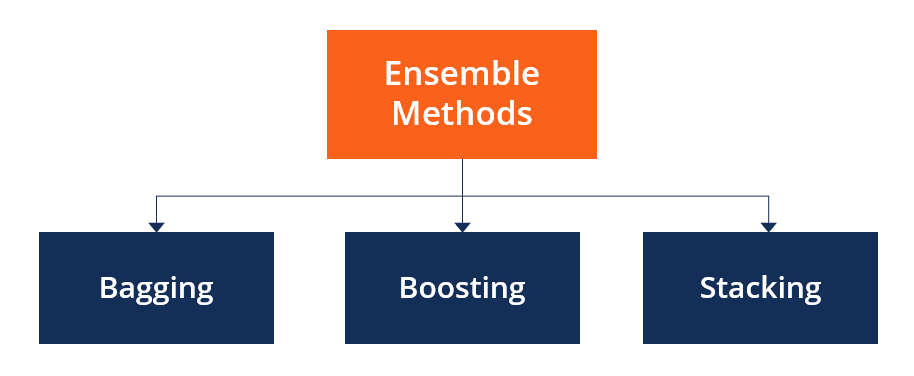
- Ensemble Methods
Ensemble methods aim to improve the accuracy of the results in models by combining multiple models instead of using a single model.
Ensemble learning helps improve machine learning trees results by combining several models. This approach allows the production of better predictive performance than any single model.
The most popular ensemble methods are bagging, boosting, and stacking.
- How To Create An Ensemble Method?
Follow these steps to create an ensemble method:
- Setting Up The Environment: Establishing the necessary tools and configurations for the project’s development.
- Understanding The Data: Gaining insights into the dataset’s characteristics, features, and patterns.
- Prepare The Data For Training: Cleaning, preprocessing, and organizing it to make it suitable for machine learning models.
- Bagging Model: Employing ensemble learning by training multiple models independently and combining their predictions for enhanced accuracy.
- Blending Model: Combining predictions from different models, often with varying algorithms or hyperparameters, to achieve a more robust and accurate final prediction.
- Types Of Ensemble Method
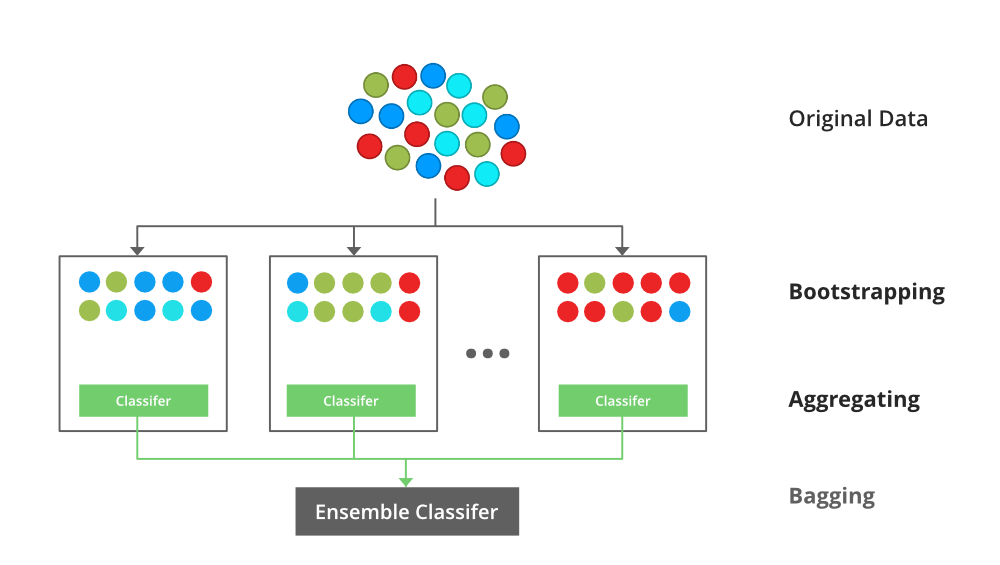
- Bagging :
Bagging is an ensemble machine-learning technique that aims to improve the stability and accuracy of a model by combining multiple instances of the same learning algorithm.
It involves training the model on different subsets of the training data, randomly sampled with replacement (bootstrap sampling). Each subset is used to train a separate model, and the final prediction is often obtained by averaging or taking a vote among the predictions of these individual models. Bagging helps reduce overfitting and variance, making it especially effective for unstable models.
- Random Forests
Random Forests is an extension of bagging that applies explicitly to decision tree models. It builds multiple decision trees during training, where each tree is trained on a different subset of the data, and at each split in the tree, a random subset of features is considered. Then, the final prediction is made by aggregating the predictions of all the trees, usually through a simple voting mechanism. Random Forests can handle high-dimensional data well and are less prone to overfitting than individual decision trees. They are widely used for classification and regression tasks in various domains.
- Gradient Boosting
Gradient Boosting is an ensemble technique that builds a strong predictive model by combining the predictions of multiple weak models, typically decision trees, sequentially. Unlike bagging, where models are trained independently, gradient boosting builds models sequentially, with each new model focusing on correcting the errors made by the previous ones.
It minimizes a loss function by adjusting the weights of individual models during training.
Gradient Boosting is known for its high predictive accuracy and is widely used in machine learning competitions. However, it requires careful tuning of hyperparameters to prevent overfitting.
- Advantages And Disadvantages Of Ensemble Method
The ensemble method has many benefits, but we cannot overlook the challenges. Let’s delve into both the advantages and disadvantages of the Ensemble method in detail.
Advantages Of The Ensemble Method:
- Decision trees require less effort as compared to other algorithms.
- It does not require scaling of data as well.
- It does not require the normalization of data.
- A decision tree does not require the normalization of data.
- A decision tree does not require scaling of data as well.
- Missing values in the data also do not affect the process of building a decision tree to any considerable extent.
- A Decision tree model is intuitive and easy to explain to technical teams and stakeholders.
Disadvantages Of The Ensemble Method:
Here are some of the disadvantages of the Ensemble Method:
- A small change in the data can cause a significant change in the structure of the decision tree, causing instability.
- For a Decision tree, sometimes calculation can be far more complex than other algorithms.
- Decision tree often involves more time to train the model.
- Decision tree training is relatively expensive as the complexity and time are higher.
- The Decision Tree algorithm is inadequate for applying regression and predicting continuous values.
Use Of Tree-Based Models In Machine Learning
Tree-based models are machine-learning models that use a decision tree as a predictive model. These models are widely used in various applications due to their interpretability, flexibility, and high performance.
Tree-based models find applications in various domains, including finance, healthcare, and marketing. They are powerful tools for both beginners and experienced practitioners due to their ability to handle complex relationships in data and provide insights into feature importance.
In detail, let’s discuss some key tree-based models and their use in machine learning:
- Decision Trees
ML Decision trees are versatile tree models that can be used for classification and regression tasks. They are especially beneficial when a complex relationship exists between features and the target variable.
- Random Forest
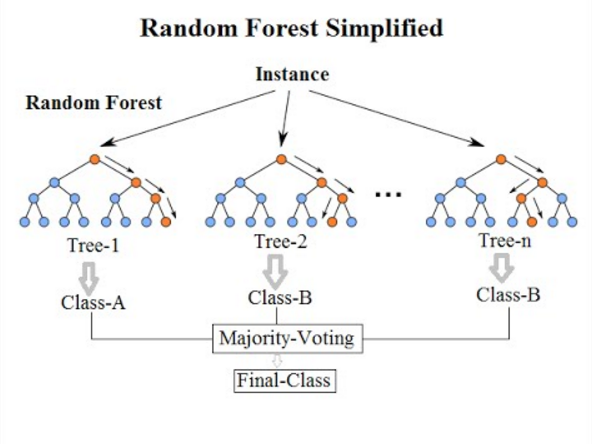
Random Forest is an ensemble method that builds multiple decision trees and merges their predictions. This model is effective in classifications and regression tasks and is popular for its high accuracy and robustness.
- Gradient Boosting Machines
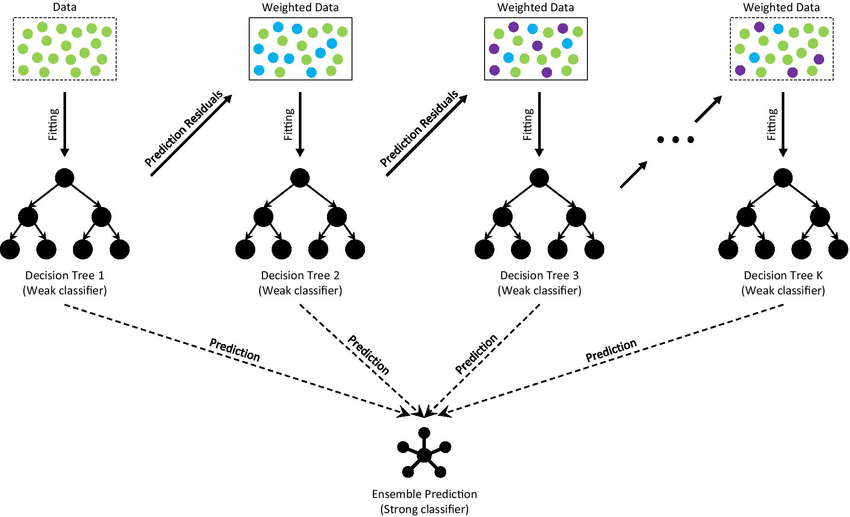
Gradient Boosting Machines(GBM)builds trees sequentially, with each tree correcting errors made by the previous ones. It is effective for regression and classification tasks and is known for its high predictive accuracy.
- XGBoost
XGBoost is an optimized and scalable version of gradient boosting. It has wide use in machine learning competitions and real-world applications due to its speed and performance.
- LightGBM
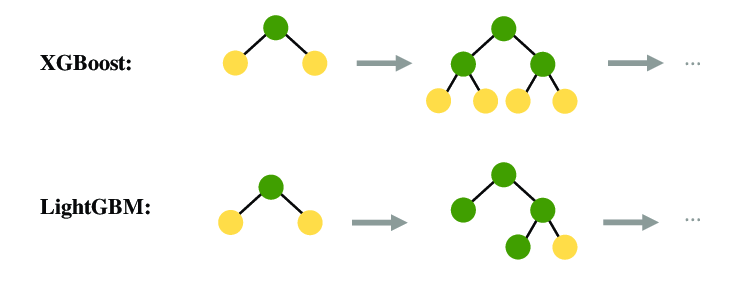
LightGBM is another gradient-boosting framework designed for distributed and efficient training. It is especially useful for large datasets and is known for its speed.
- CatBoost

CatBoost is a gradient-boosting library that is particularly effective with categorical features. It is designed to handle categorical data without the need for extensive preprocessing.
Implementation Of Tree-Based Models In Machine Learning
Tree-based models in machine learning are a prominent category that offers a versatile framework for decision-making. These models, such as decision trees, random forests, and gradient boosting, excel in handling classification and regression tasks.
- Implementing tree-based ML models involves constructing hierarchical structures where nodes represent decision points based on input features.
- The training process optimizes these structures to make accurate predictions.
- Tree-based models are valued for their interpretability, scalability, and ability to capture complex relationships within data.
- They have proven effective in various domains, showcasing their adaptability and performance across various machine-learning applications.
Advantages Of Tree-Based Models
Tree-based models offer several advantages that contribute to their popularity in machine learning.
- Improved Accuracy
Tree-based models excel at providing improved accuracy. They serve like a reliable compass in a dense forest, accurately navigating every twist and turn in the data landscape. The precision of the tree-based models makes them a trusted companion in sectors from finance to healthcare.
- Handling Non-Linearity
Tree-based models easily navigate through non-linear intricacies with ease. This ability to capture complex relationships allows them to uncover patterns that might be elusive to simpler, more linear models.
- Reduction of Overfitting
Tree-based models follow a similar principle. They avoid overfitting, ensuring that the model doesn’t just memorize the training data but genuinely understands the underlying principles. This makes them adaptable to new scenarios, preventing them from repeating the same pattern blindly.
- Versatility Across Algorithms
Tree-based models seamlessly adjust to different tree-based algorithms. Whether classification, regression, or something in between, these models showcase their versatility in handling several tasks.
- Handling Different Views Of The Data
Tree-based models can accommodate different views of the data. This flexibility makes them valuable in situations where the interpretation of data can vary. They possess the unique ability to understand and work with diverse data views.
- Enabling Model Combination
Tree-based models excel at combining multiple models to create a powerful ensemble. They enable model combination, creating a harmonious blend of predictions. Each model contributes unique strengths, resulting in a collective predictive power surpassing individual efforts.
- Enhanced Stability
Vast data can get unpredictable. Tree-based models, however, bring a sense of stability to the chaotic nature of information. These models remain resilient to small variability. This stability ensures reliable predictions even when the data gets challenging.
- Flexibility In Model Selection
Tree-based models offer a diverse selection of models to suit various tasks. Be it a casual regression or a formal classification event, there’s a model that fits just right.
- Easy Parallelization
Tree-based models provide efficiency with their easy parallelization. Each tree can work independently, speeding up the learning process and ensuring the performance is well-coordinated even with a vast dataset.
10. Wider Applicability
The wide applicability of tree-based models spans industries from predicting customer behavior to diagnosing medical conditions. Tree-based models are versatile tools indispensable across the varied terrains of data science.
11. Interpretability
Understanding the why behind decisions is crucial, and tree-based models provide this insight. Tree-based models make their predictions comprehensible, building trust and understanding in their users.
Challenges Of Tree-Based Models
Here’s an elaborative list of challenges of the tree-based models.
- Overfitting:
- Decision trees, especially when deep, tend to overfit the training data, capturing noise and outliers that may not generalize well to unseen data.
- Random Forests and gradient-boosted trees mitigate overfitting to some extent, but tuning hyperparameters like tree depth is crucial to finding the right balance.
- Interpretability:
As tree-based models become more complex, they can be challenging to interpret, especially for deep trees or ensembles. Understanding the decision-making process may be difficult, making it hard to communicate the model’s insights to non-technical stakeholders.
- Computational Complexity:
Training a large number of deep trees, especially in the case of ensembles like Random Forests and Gradient Boosted Trees, can be computationally expensive and time-consuming.
- Sensitive To Small Variations In Data:
Tree-based models are sensitive to minor variations in the training data. A slight data change or a random seed during training might lead to a significantly different tree structure or model performance.
- Hyperparameter Tuning:
Tuning hyperparameters for tree-based models can be challenging. The number of trees, tree depth, learning rate (for Gradient Boosting), and other parameters must be carefully selected to achieve optimal performance without overfitting.
- Imbalanced Data:
Tree-based models may not perform well on imbalanced datasets, where one class significantly outnumbers the others. They may have a bias towards the majority class, and techniques such as class weighting or resampling may be needed to address this issue.
- Lack Of Extrapolation:
Tree-based models are typically not good at extrapolating patterns beyond the range of the training data. If the test data contains values outside the range of the training data, the model may not make accurate predictions.
- Handling Missing Data:
Decision trees can handle missing values, but imputation strategies are needed for Random Forests and Gradient Boosted Trees. The handling of missing data can impact model performance.
- Limited Expressiveness For Some Relationships:
Tree-based models may struggle to capture complex relationships, especially those involving feature interactions. More sophisticated models like neural networks might be more suitable in such cases.
Wrapping Up
Tree-based models like decision trees, random forests, and gradient boosting are powerful tools in machine learning. They’re great at understanding and handling complex relationships in different areas. Despite some challenges like overfitting, knowing their pros and cons helps users make the most of these models. Whether you’re a beginner or an expert, learning how to use tree-based models can boost accuracy and improve decision-making in machine learning.

FAQ
- What Is The Difference Between A Decision Tree And A Classification Tree?
Regression trees handle outcomes that are numbers, while classification trees deal with outcomes that are categories or labels.
- What Is The Use Of ML And AI?
AI involves software replicating human thinking to tackle complex tasks and learn, while machine learning, a part of AI, utilizes data-trained algorithms to generate adaptable models for various complex tasks.
- Can Tree Diagrams Be Used For Data Visualization?
Yes, tree diagrams are commonly used for visualizing hierarchical data structures, such as file systems, organizational structures, and product categorizations.
- Can Tree Diagrams Be Used For Brainstorming And Idea Generation?
Tree diagrams are valuable aids in brainstorming sessions, aiding in the organization and visualization of ideas while promoting a structured thought process.