
PDFs play a significant role in the world of data science where information comes in various forms. Whether it’s research papers, reports, or datasets, dealing with PDF documents is inevitable.
Luckily, data scientists can leverage tools to extract, compress, and merge PDF data to improve their data workflow.
In this blog post, we’ll explore how integrating these tools can streamline data processes and optimize the overall PDF workflow.
Streamlining Data Extraction
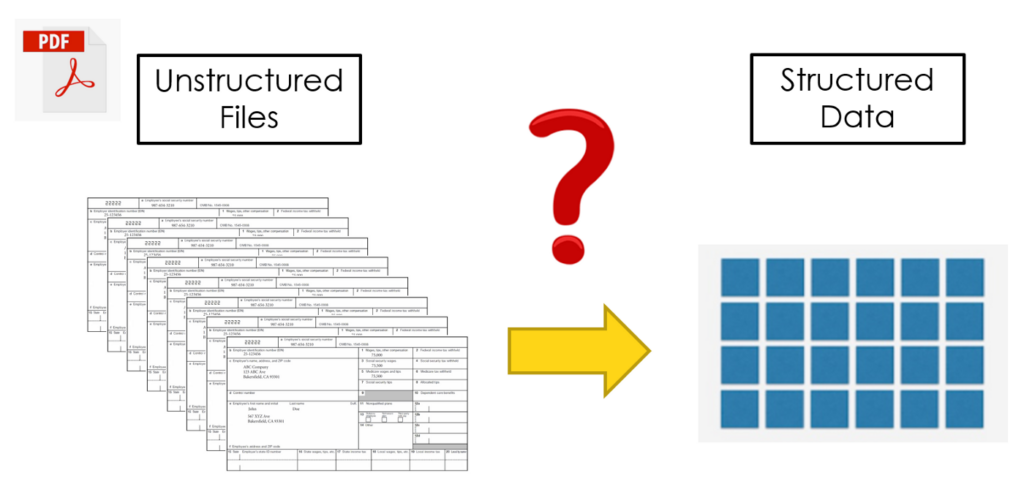
Data scientists frequently encounter the need to extract valuable information from PDF, whether it’s for analysis, reporting, or collaboration. Traditional methods, often involving manual copying and pasting, can be time-consuming and error prone.
This is where the power of PDF extraction tools comes into play. These tools empower data scientists to efficiently retrieve relevant data from PDFs without compromising its integrity.
Consider a scenario where a data scientist is tasked with extracting tabular data from a research report for further analysis in MS Excel. Utilizing a PDF extraction tool, the process becomes streamlined. Data scientists can seamlessly convert tables from PDF into Excel spreadsheets, enhancing the accessibility and usability of the data.
Merging PDFs for Comprehensive Analysis
In many data science projects, information is scattered across multiple PDF documents. It could be datasets, reports, or research findings. Merging these documents into a consolidated resource can significantly improve the efficiency of analysis.
For instance, consider a project where a data scientist is working with several reports, each containing valuable insights. Instead of flipping between multiple documents, merging these reports into a single PDF provides a holistic view. PDF merging tools make this process seamless, allowing data scientists to create a comprehensive document that encapsulates all relevant information.
This approach not only saves time but also enhances the accessibility of data. It becomes particularly useful when presenting findings or sharing results with stakeholders, as a consolidated document simplifies communication.
Compression for Efficient Data Storage and Transfer
As datasets and reports grow in size, efficient storage and transfer become crucial. Large PDF files can consume valuable storage space and may pose challenges when sharing or collaborating on projects. This is where file compression plays a vital role.
Compression tools help reduce the size of PDF files without significantly compromising the quality of the data. For data scientists working with large datasets or sharing reports across teams, compressed PDFs offer a practical solution. Smaller file sizes ease the burden on storage systems and make it more convenient to transfer files, especially in scenarios where bandwidth is a limiting factor.
Consider a data scientist working on a machine learning project with extensive documentation. Compressing the PDF containing project specifications, code snippets, and results not only saves storage space but also facilitates quicker sharing with team members.
Automated Workflows with PDF Tools
To truly harness the power of PDF extraction, merging, and compression, data scientists can integrate these tools into their automated workflows. Automation not only saves time but also ensures consistency and reproducibility in data processes.
Let’s take Python as an example. Leveraging libraries such as PyPDF2 for PDF extraction, PyPDFMerger for merging, and PyMuPDF for compression, data scientists can script these processes. This allows for the creation of customized workflows that can be easily adapted to different projects.
Here’s a simple example in Python for extracting text from PDF:
import PyPDF2
def extract_text_from_pdf(pdf_path):
with open(pdf_path, 'rb') as file:
pdf_reader = PyPDF2.PdfReader(file)
text = ''
# Extract text from each page
for page_num in range(len(pdf_reader.pages)):
text += pdf_reader.pages[page_num].extractText()
return text
# Example usage
pdf_path = 'example.pdf'
extracted_text = extract_text_from_pdf(pdf_path)
print(extracted_text)
Best Practices for Integrated PDF Workflows
While integrating PDF tools into data science workflows, it’s essential to follow best practices to maintain data integrity and ensure optimal results.
Document Changes
When using PDF editing tools, document the changes made to the original file. This not only aids in version control but also ensures transparency in collaborative projects.
Test Compression Levels
Experiment with different compression levels to find the right balance between file size reduction and data quality. Some tools allow for adjusting compression settings to meet specific project requirements.
Keep Backups
Before applying any edits, merging, or compression, always keep backups of the original PDF files. This precautionary step prevents data loss in case unexpected issues arise.
Version Control
Implement version control practices, especially when working on collaborative projects. This ensures that changes are tracked, and previous versions of documents can be revisited if needed.
Streamline Automation
When automating workflows, organize code and scripts in a way that facilitates easy integration with other data science tools. Maintain clear documentation for future reference and collaboration. 
Optimize Your Workflows with PDF Tools
In the dynamic field of data science, optimizing workflows is key to staying efficient and productive. Integrating PDF extraction, merging, and compression tools into data processes enhances the overall workflow, making it easier for data scientists to manage, analyze, and share information. By automating these tasks and following best practices, data scientists can unlock the full potential of PDF tools, ensuring a seamless and productive data science journey.