Issues with performance measures in machine learning
When testing a predictive model, choosing the correct performance measure is imperative for making sure our model works correctly. In machine learning literature, however, it is common to use measures because they have always been used in the past, without really judging whether they are the best ways to measure the performance in the current problem.
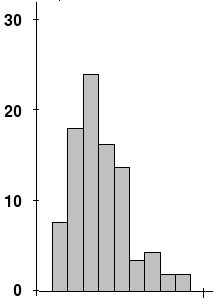
The most common problematic measure are the Root Mean Squared Error (RMSE) for regression and the accuracy for classification. The RMSE penalizes larger errors more than smaller errors. However, for problems where the response variable is right skewed, the error can be severely affected by a few data points on the right end of the tail.
A way to handle this might be to use other measures such as the mean absolute error or the correlation between predicted and true values.
Similarly, the accuracy is a bad measure when the classes are highly imbalanced. In a binary classification problem where 5% is of class B and 95% class A, it is trivial to achieve 95% accuracy. That’s a mistake I’ve seen newcomers to machine learning doing. There are different measures such as the kappa statistic or the F-measure that can handle imbalanced classes.
There is a recently published book regarding performance metrics in classification called “Evaluating Learning Algorithms: A Classification Perspective“. I would highly recommend it to any one starting in machine learning and predictive modelling.

Quick tips and tricks for performance measures
In any case, I won’t be going into much detail into each individual measure here, since these will be covered in future posts. However, I will cover two simple tricks.
- When you are on doing regression, plot a histogram of the response. If it is extremely skewed go with the mean absolute error , instead of the RMSE.
- When you are doing classification, check how balanced the classes are. If they are highly imbalanced, use the kappa statistic. Values close to 1 indicate better performance.
- A good choice for multiclass problems is the F1 score.
I have written some other articles about alternatives to commonly used performance measures in machine learning. More specifically, I’ve written about the use of the concordance correlation coefficient for evaluating regression models, and the use of Cohen’s kappa in multiclass problems. Obviously there are many more measures. Scikit-learn has good coverage and can be a good starting point.
So, next time you are using the RMSE or the accuracy, make sure you are doing the right thing!