
An Introduction to Anomaly Detection and Its Importance in Machine Learning
Data is becoming increasingly important in almost every conceivable field and area. From business and healthcare to law enforcement and sports, data is central to their operations. It’s not enough to simply collect information however. Instead, you need to make good use of it, and this is where data science comes into play. Anomaly detection is one of the most interesting applications of data science, and in this article I will provide a brief overview of what it is, and how it can be used.
What Is Anomaly Detection?
Anomaly detection involves identifying the differences, deviations, and exceptions from the norm in a dataset. It’s sometimes referred to as outlier detection (i.e., looking at a dataset to identify any outlying or unusual datapoints, data groups, or activity).
For example, credit card companies collect data on everything we purchase, including the amount of money we spend, where we spend it, what we spend it on, how frequently we make purchases, and more.
Anomaly detection makes this data not only useful but powerful. This is because anomaly detection algorithms analyse all the data above to identify fraudulent credit card activity within seconds of a transaction taking place.
What Are the Applications of Anomaly Detection?
There are many applications for anomaly detection:
- Cybersecurity – Network intrusion is a prominent example. One way an anomaly detection algorithm would do this would be by monitoring traffic to establish normal levels and then identifying anything that falls outside this norm.
- Fraud detection – This was mentioned above with the credit card example.
- Social media monitoring – To get a better understanding of user activity and engagement on social media as well as other forms of digital marketing and advertising, anomaly detection might identify that searches for a particular topic spike at certain times of the year, enabling advertisers and marketers to allocate their budgets accordingly.
- Machine performance – Digital twin technologies are a good example in this instance. A digital twin is an exact digital replica of a real-world machine, process, or piece of equipment. Anomaly detection can identify deviations in performance in the digital twin that are early warning signals of an impending failure in the real-world machine. This makes it possible to schedule maintenance of the machine before the failure occurs, reducing downtime and improving productivity.
- Medical monitoring – This is everything from identifying abnormal patterns or occurrences in an individual (such as an irregular heartbeat) to identifying health-related anomalies in groups of people, such as the unusual spread of a disease over a short period of time in a particular geographical area.
Of course, there are many more applications of anomaly detection than those listed above. The crucial point is the fact that anomaly detection is becoming increasingly important and that it enables data to be used in ways it never was before.
Different Types of Anomalies in Anomaly Detection
Not all anomalies are equal. In fact, they can be split into three broad categories:
- Point anomalies
- Collective anomalies
- Contextual anomalies
Let’s look at each in more detail.
Point Anomalies
A point anomaly is where a single datapoint stands out from the expected pattern, range, or norm. In other words, the datapoint is unexpected.
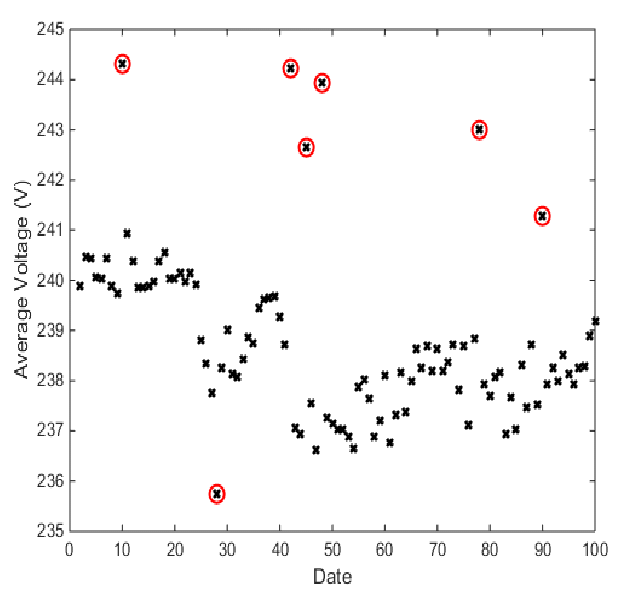
We can again turn to credit card spending as an example. A point anomaly would be a single, high-value, and unusual spend on a credit card. For example, normal spending on a credit card might be small to medium-sized amounts, typically within the same geographical area and usually to purchase a similar group of products.
A point anomaly would be if that credit card was then used to make a single high-value purchase for an item not previously purchased and purchased in a location where the credit card has not been used before.
This point anomaly could indicate fraudulent activity.
Scikit-learn has good support for point anomaly detection algorithms, such as LOF.
Collective Anomalies
A collective anomaly occurs where single datapoints looked at in isolation appear normal. When you look at a group of these datapoints, however, unexpected patterns, behaviours, or results become clear.
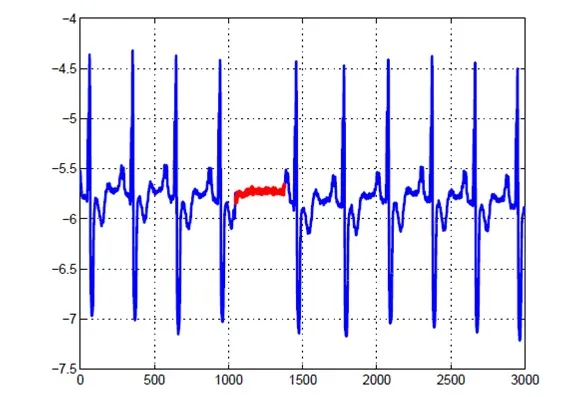
Those unexpected occurrences could be, for example, events occurring in an order or in a combination that is unexpected.
We can use potential credit card fraud as our example again. This would occur where multiple purchases appear to fit within normal spending activity when looked at individually. When you look at these purchases as a group, however, unusual patterns and behaviour can appear.
Contextual Anomalies
Instead of looking at specific datapoints or groups of data, an algorithm looking for contextual anomalies will be interested in unexpected results that come from what appears to be normal activity.
The crucial element here is context: Are the results out of context?
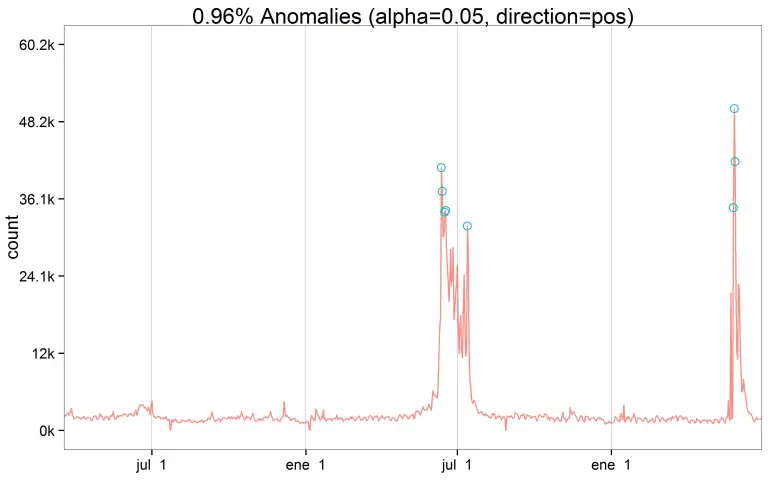
A good example in this instance is a network intrusion attempt. An algorithm looking for contextual anomalies will have a baseline of activity that provides it with normal parameters. This could, for example, show the expected levels of traffic accessing the network at various times of the day.
Traffic might be at its lowest in the early hours of the morning. Therefore, a spike in traffic at 3 a.m. is a contextual anomaly that warrants further action and/or investigation as it could indicate a network intrusion attempt.
In other words, accessing the network in itself was a completely normal event. Having such high levels of traffic at three in the morning, however, was unusual; it was an anomaly.
Do you want to become data scientist?

Do you want to become a data scientist and pursue a lucrative career with a high salary, working from anywhere in the world? I have developed a unique course based on my 10+ years of teaching experience in this area. The course offers the following:
- Learn all the basics of data science (value $10k+)
- Get premium mentoring (value at $1k/hour)
- We apply to jobs for you and we help you land a job, by preparing you for interviews (value at $50k+ per year)
- We provide a satisfaction guarantee!
If you want to learn more book a call with my team now or get in touch.