
Natural Language Processing (NLP) is the branch of data science primarily concerned with dealing with textual data. It is the intersection of linguistics, artificial intelligence, and computer science.

NLP deals with human-computer interaction and helps computers understand natural language better. The main goal of Natural Language Processing is to help computers understand language as well as we do.
It has numerous applications including but not limited to text summarization, sentiment analysis, language translation, named entity recognition, relation extraction, etc.
Natural Language Processing is considered more challenging than other data science domains. This is due to a number of reasons.
It can convey the same meaning using multiple different combinations of words.
Natural Language is also ambiguous, the same combination of words can also have different meanings, and sometimes interpreting the context can become difficult.
Thus, it can become challenging when working with natural language.
Syntactic Analysis Vs Semantic Analysis

Two primary ways to understand natural language are syntactic analysis and semantic analysis.
The syntactic analysis deals with the syntax of the sentences whereas, the semantic analysis deals with the meaning being conveyed by those sentences.
An important thing to note here is that even if a sentence is syntactically correct that doesn’t necessarily mean it is semantically correct.
Syntactic Analysis
In syntactic analysis, we use rules of formal grammar to validate a group of words. With syntactic analysis, we validate the structure of our sentences.
Semantic Analysis
Semantic analysis deals with the part where we try to understand the meaning conveyed by sentences. This will allow computers to understand natural language better.
It still remains largely unsolved and more work is being done on it.
Popular Natural Language Processing Packages
Some of the most popularly used packages for different NLP methods are the following:
NLTK

Natural Language Toolkit or NLTK is one of the widely used NLP packages to deal with human language data. It comes with numerous unstructured data and human-readable text.
Using NLTK we can easily process texts and understand textual data better.
Spacy

Spacy is another popular NLP package and is used for advanced Natural Language Processing tasks. It contains a lot of state-of-the-art models for several different problems.
It is an open-source package that was created with the purpose that it’ll be used to build real products.
Hugging Face

Hugging Face is the most popular NLP package out there right now.
It is an open-source package with numerous state-of-the-art models that can be applied to solve various different problems.
They also have numerous datasets and courses to help NLP enthusiasts get started.
Before we move on to the next part, let’s import all the necessary libraries that we will be using in this tutorial.import spacy import nltk import gensim from nltk.corpus import stopwords from nltk.stem import WordNetLemmatizer from nltk.stem import PorterStemmer from nltk.tokenize import word_tokenize from nltk import ngrams from sklearn import preprocessing import gensim.downloader as API
Data Cleaning in NLP
The data cleaning process largely depends on the problem that we are working on. But normally, what we do is remove any special characters such as $, %, #, @, <, >, etc.
These symbols don’t hold any information for our model to learn. They act as noise in our data so, we discard them.
Data Preprocessing in NLP
There are a number of NLP methods to preprocess data. In this data science tutorial, we will be going over some of them.
Lowercase
If any character in our text is in uppercase we convert it to lowercase. Otherwise, our model will perceive the uppercase and lowercase characters as different from each other.
This will cause problems when parsing the text later on.
For example, the sentence “The dog belongs to Jim” would be converted to “the dog belongs to him”.
Let’s take a look at how to convert our textual data to lowercase. text_data = """ Let's convert this demo text to Lowercase for this NLP Tutorial using NLTK. NLTK stands for Natural Language Toolkit """ lower_text = text_data.lower() print (lower_text)
Output: let’s convert this demo text to lowercase for this nlp tutorial using nltk. nltk stands for natural language toolkit
Tokenization
In tokenization, we take our text from the documents and break them down into individual words.
For example “The dog belongs to Jim” would be converted to a list of tokens [“The”, “dog”, “belongs”, “to”, “Jim”].
Now we will take our textual data and make word tokens of our data. Then we will be printing them.word_tokens = word_tokenize(text_data) print(word_tokens)
Output: [‘Let’, “‘s”, ‘convert’, ‘this’, ‘demo’, ‘text’, ‘to’, ‘Lowercase’, ‘for’, ‘this’, ‘NLP’, ‘Tutorial’, ‘using’, ‘NLTK’, ‘.’, ‘NLTK’, ‘stands’, ‘for’, ‘Natural’, ‘Language’, ‘Toolkit’]
Stopwords Removal
We remove words from our text data that don’t add much information to the document. So, they add noise to the data.
For different domains, it is possible that the stop words may differ from each other.
Consider an example, if “the” and “to” our some tokens in our stopwords list, when we remove stopwords from our sentence “The dog belongs to Jim” we will be left with “dog belongs Jim”.
Stop words don’t hold a great deal of information so it is better to remove them since they act as noise in our data. We getstopword = stopwords.words('english') removing_stopwords = [word for word in word_tokens if word not in stopword] print (removing_stopwords)
Output: [‘Let’, “‘s”, ‘convert’, ‘demo’, ‘text’, ‘Lowercase’, ‘NLP’, ‘Tutorial’, ‘using’, ‘NLTK’, ‘.’, ‘NLTK’, ‘stands’, ‘Natural’, ‘Language’, ‘Toolkit’]
Stemming
In stemming we reduce a word to its root word. It transforms the word back to its original form i.e reduces inflection.
Thus, we are only left with the stem words.
For example, when we apply stemming on “Caring”, we will be left with “Car”.
Using stemming, we can reduce a word to its original form but it is important to note here that it doesn’t always have some meaning. With the following code, we can reduce a word to its root word. We’ll be using the Porter Stemmer since it is one of the most commonly used stemmers.ps = PorterStemmer() stemmed_words = [ps.stem(word) for word in word_tokens] print(stemmed_words) Output: [‘let’, “‘s”, ‘convert’, ‘thi’, ‘demo’, ‘text’, ‘to’, ‘lowercas’, ‘for’, ‘thi’, ‘nlp’, ‘tutori’, ‘use’, ‘nltk’, ‘.’, ‘nltk’, ‘stand’, ‘for’, ‘natur’, ‘languag’, ‘toolkit’]
Lemmatization
Lemmatization does the same thing as stemming but in lemmatization, we get a root word that has some meaning.
Whereas stemming from the root word may or may not have any meaning.
For example, when we apply lemmatization on “Caring” we will be left with “Care”.
Lemmatization is similar to Stemming but in the case of lemmatization, the reduced word will have some meaning. Now we’ll take a look at how to perform lemmatization using Python. We’ll be using a different list of tokens to be able to see better how lemmatization works. wnl = WordNetLemmatizer() word_tokens2 = ["corpora","better","rocks","care","classes"] lemmatized_word = [wnl.lemmatize(word) for word in word_tokens2] print (lemmatized_word)
Output: [‘corpus’, ‘better’, ‘rock’, ‘care’, ‘class’]
N Grams
N Grams are used to preserve the sequence of information which is present in the document.
When N = 1, they are called Unigrams. When N = 2, they are called bigrams. When N = 3, they are called trigrams. And so on.
In unigrams, since each word is taken individually, no sequence information is preserved.
For example, “Today is Monday.”
Unigrams = Today, is, Monday
Bigrams = Today is, is Monday
Trigrams = Today is Monday
Let’s see how we can convert our text data to N-grams. Over here the value of N will be 3, so we’ll be making trigrams. n_grams = ngrams(text_data.split(), 3) for grams in n_grams: print(grams)
Output: (“Let’s”, ‘convert’, ‘this’)
(‘convert’, ‘this’, ‘demo’)
(‘this’, ‘demo’, ‘text’)
(‘demo’, ‘text’, ‘to’)
(‘text’, ‘to’, ‘Lowercase’)
(‘to’, ‘Lowercase’, ‘for’)
(‘Lowercase’, ‘for’, ‘this’)
(‘for’, ‘this’, ‘NLP’)
(‘this’, ‘NLP’, ‘Tutorial’)
(‘NLP’, ‘Tutorial’, ‘using’)
(‘Tutorial’, ‘using’, ‘NLTK.’)
(‘using’, ‘NLTK.’, ‘NLTK’)
(‘NLTK.’, ‘NLTK’, ‘stands’)
(‘NLTK’, ‘stands’, ‘for’)
(‘stands’, ‘for’, ‘Natural’)
(‘for’, ‘Natural’, ‘Language’)
(‘Natural’, ‘Language’, ‘Toolkit’)
Word Vectorization
In order to help machines understand textual data, we have to convert them to a format that will make it easier for them to understand the text.
This is why we convert text to numbers. There are many NLP methods to convert text to numbers, but we’ll be covering some of them in this article.
Word vectors or word embeddings are textual data mapped to real numbers.
After numbers have been converted to word vectors, we can perform a number of operations on them. Such as, finding similar words, classifying text, clustering documents, etc.
Now let’s discuss some methods for converting words to word vectors.
One Hot Vector Encoding
In one-hot vector encoding, we made embeddings of the entire corpus. In these types of word vectors, all the words are independent of each other.
We couldn’t find the dependence of one word on other words. So, they weren’t of much use to us.
While making a one-hot encoded vector, it simply placed a 1 where the word was and 0 everywhere else in the vector.
Let’s see how we can convert our text to one-hot encoded vectors. We’ll be using a different list of tokens to better understand how one hot encoding works.word_tokens3 = ['corpora', 'better', 'rocks', 'care', 'classes','better','apple'] lab_encoder = preprocessing.LabelEncoder() int_label_encoder = lab_encoder.fit_transform(word_tokens3) lab_encoded = int_label_encoder.reshape(len(int_label_encoder),1) one_hot_encoder = preprocessing.OneHotEncoder(sparse=False) one_hot_encoded = one_hot_encoder.fit_transform(lab_encoded) print(one_hot_encoded) print(word_tokens3) Output: [[0. 0. 0. 0. 1. 0.]
[0. 1. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 1.]
[0. 0. 1. 0. 0. 0.]
[0. 0. 0. 1. 0. 0.]
[0. 1. 0. 0. 0. 0.]
[1. 0. 0. 0. 0. 0.]]
[‘corpora’, ‘better’, ‘rocks’, ‘care’, ‘classes’, ‘better’, ‘apple’]
Word2Vec
With word2vec, we were able to form a dependence of words with other words. These were a considerable improvement over One Hot Vector.
One hot vector didn’t consider context whereas, word2vec does consider the context. Thus, we can use them to find word similarities.
Now let’s see how we can make Word2Vec vectors of our data. We won’t be training a Word2Vec model from scratch, we’ll just load a pre-trained Word2Vec model using Gensim which is another important package for different NLP methods.model = api.load("word2vec-google-news-300") model.most_similar("obama") Output: [(‘romney’, 0.9566564559936523),
(‘president’, 0.9400959610939026),
(‘barack’, 0.9376799464225769),
(‘clinton’, 0.9285898804664612),
(‘says’, 0.9087842702865601),
(‘bill’, 0.9080009460449219),
(‘claims’, 0.9074634909629822),
(‘hillary’, 0.8889248371124268),
(‘talks’, 0.8864543437957764),
(‘government’, 0.8833804130554199)]
Let’s go through some different methods to create Word2Vec vectors. The following are two methods we can use to obtain word2vec vectors:
CBOW Model
In the CBOW (continuous bag of words) model, we predict the target (center) word using the context (neighboring) words.
The CBOW model is faster than the skip-gram model because it requires fewer computations and it is great at representing less frequent words.
Skip Gram Model
With Skip Gram, we predict the context words using the target word.
Even though the skip-gram model is a bit slower than the CBOW model, it is still great at representing rare words.
Named Entity Recognition
Now we’ll be going through one of the important NLP methods for recognizing entities. It’s called named entity recognition.
Named Entity Recognition is an important information retrieval technique.
To understand the working of named entity recognition, look at the diagram below.
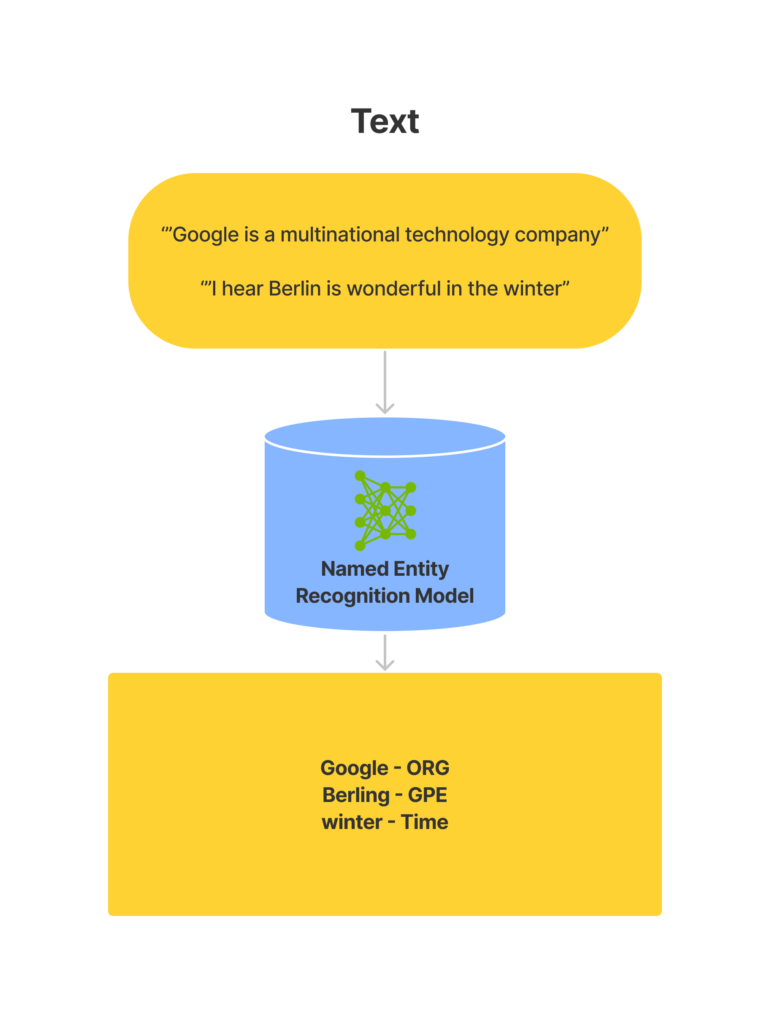
From the above diagram, we can see that a named entity recognition model takes text as input and returns the entities along with their labels present in the text.
It has numerous applications. It can be used for content classification, using it we can detect entities in text and classify the content based on those entities.
In academia and research, it can be used for retrieving information faster.
Now let’s take a look at how we can do NER in python. First we’ll load a pre-trained spacy pipeline which is trained on numerous different forms of textual data. Using that, we can use different NLP methods. For now let’s take a look at NER.
nlp = spacy.load("en_core_web_sm") # Process whole documents text = ("When Sebastian Thrun started working on self-driving cars at " "Google in 2007, few people outside of the company took him " "seriously. “I can tell you very senior CEOs of major American " "car companies would shake my hand and turn away because I wasn’t " "worth talking to,” said Thrun, in an interview with Recode earlier " "this week.") doc = nlp(text)
# Find named entities, phrases and concepts for entity in doc.ents: print(entity.text, entity.label_)
Output: Sebastian Thrun PERSON
2007 DATE
American NORP
Thrun PERSON
Recode ORG
earlier this week DATE
Natural language processing summary
In this data science tutorial, we looked at different methods for natural language processing, also abbreviated as NLP. We went through different preprocessing techniques to prepare our text to apply models and get insights from them. We discussed word vectors and why we use them in NLP. Then we used NER to identify entities and their labels in our text.
If you want to learn more about data science or become a data scientist, make sure to visit Beyond Machine. If you want to learn more about topics such as executive data science and data strategy, make sure to visit Tesseract Academy.