Data is being generated at a rapid rate. From Large scale to small-scale businesses and individuals, everyone is generating data. In order to make the most of it, each and every single aspect of data needs to be analyzed. This is where “data analytics” comes in. Data analytics uses the raw data and makes conclusions about the information which allows stakeholders to make data-driven decisions.
Data analytics belongs to the same family as data science but data science involves a lot more programming.
Data analytics is the process of examining data and extracting meaningful information from it. It is a way of quantifying and analyzing the data that is collected.
Data analytics can be used to predict future trends, make decisions, and solve problems. Data analytics can be used in many different industries including healthcare, finance, retail, and education.
The goal of data analytics is to extract insights from data that will help organizations make better decisions in the future.
The process of data analysis includes four steps: collecting the data, preparing the data for analysis, analyzing the data to find insights or patterns, and communicating those insights or patterns back to stakeholders in an understandable way
Types of Data Analytics
Following are the four main types of data analytics:
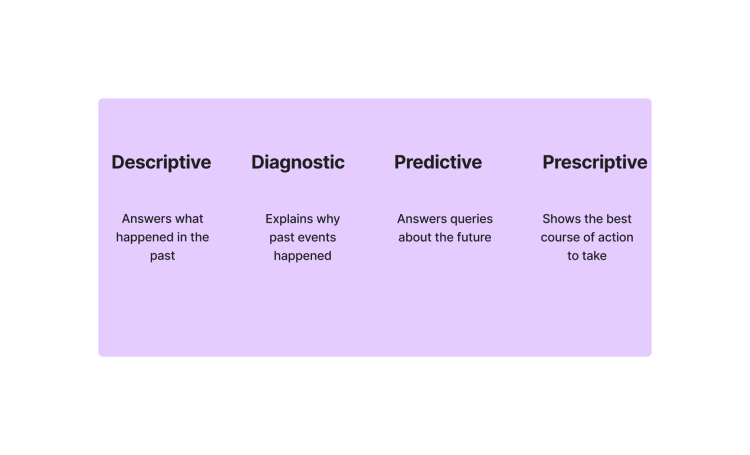
Descriptive Analytics
The main goal of descriptive analytics is to answer the question “what”.
Descriptive analytics summarizes the data and tries to answer the question of what happened in the past.
Diagnostic Analytics
Diagnostic analytics digs deeper into descriptive analytics and tries to explain why past events happened.
Instead of focusing on what happened in the past, diagnostic analytics tries to answer why an anomaly or any occurrence occurred in your data.
Predictive Analytics
In Predictive analytics, a data analyst observes the history and tries to predict future events.
It is a form of advanced analytics and mostly comes under the branch of data science.
In this analytics, we take historical data and use it to make forecasts about when will the parts break down, future sales, etc.
Prescriptive Analytics
Prescriptive analytics guides you to take the best course of action. It merges predictive and descriptive analytics to make data-driven decisions.
Thus, guiding you in a direction to take a specific action.
Tools for Data Analytics: Python and R
Python comes with numerous packages and tools which can be used in data analytics. Python can be used for deep learning, making predictions, and making visualizations.
R is one of the most widely used tools for data analytics. R has a number of tools that can be used for statistical analysis.
Linear regression
Now let’s see a very simple example in both Python and R. We will use a linear regression model, which is the simplest regression model in existence. We will run this model in both Python and R.
In Python, we’ll be using Linear Regression from the statsmodels library to make these predictions. And in R, we’ll be using the Linear Regression model provided by native R (no external libraries required).
Below we have a code demo in Python and R of Linear Regression along with their results.
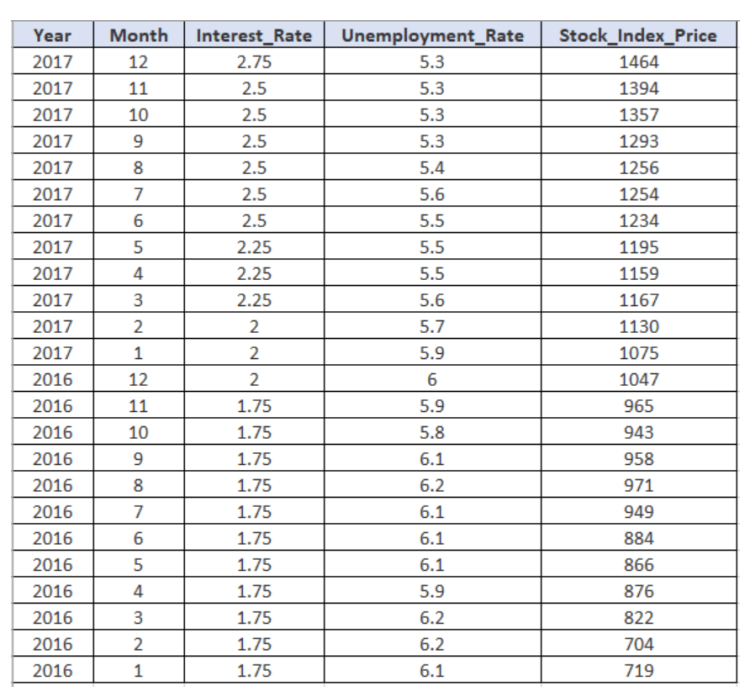
For this purpose, we’ll be loading a fictitious dataset. Here’s our dataset named:
Python example
Here’s the code in Python. The first step is to load the data. We will be using
First, we import the necessary libraries.
import json from pandas import DataFrame import statsmodels.api as sm import numpy as np
Now we will load the data which is in json format.
file = open('data.json') data = json.load(file)
Then we will convert our json data into a dataframe and rename the columns.
df = DataFrame(data,columns=['year','month','interest_rate','unemployment_rate','stock_index_price'])
Now close the json file.
file.close()
Let X be the independent variable, and let Y be the dependent variable.`
X = df['interest_rate'] Y = df['stock_index_price']
Add_constant function adds value of b (y =mx + b) to the data.
X = sm.add_constant(X)
Now fit the model on the data and make predictions.
model = sm.OLS(Y, X).fit() predictions = model.predict(X)
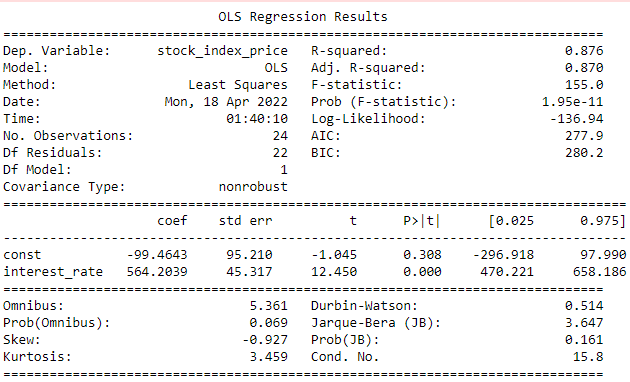
Now print the model summary, you can see it below.
print_model = model.summary() print(print_model)
After we run this, we get back the model results. The statsmodels results provide everything we expect from a statistical package. While many of the numbers here might seem a bit esoteric to fledgling data scientists, the main ones to focus on are:
-
- R-squared: A general estimation of the quality of the fit. It takes values between 0 and 1 (the higher the better).
-
- Prob (F-statistic): This is an omnibus significance test for our model. A p-value of less than 0.05 is usually taken as the model being significant.
-
- The coefficient p-values, and the direction of the effect. It looks
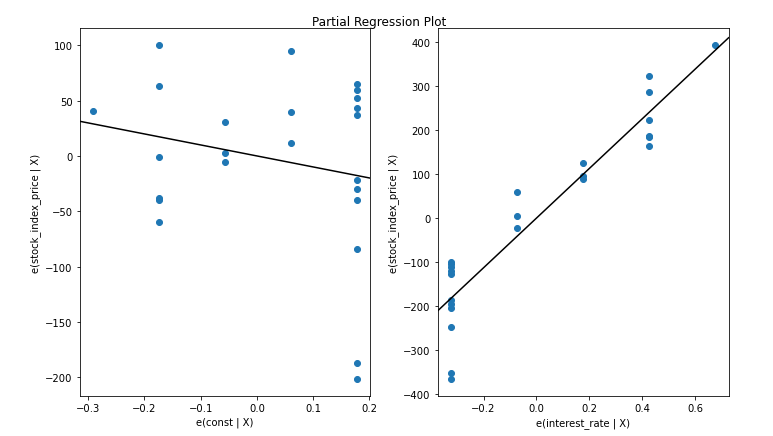
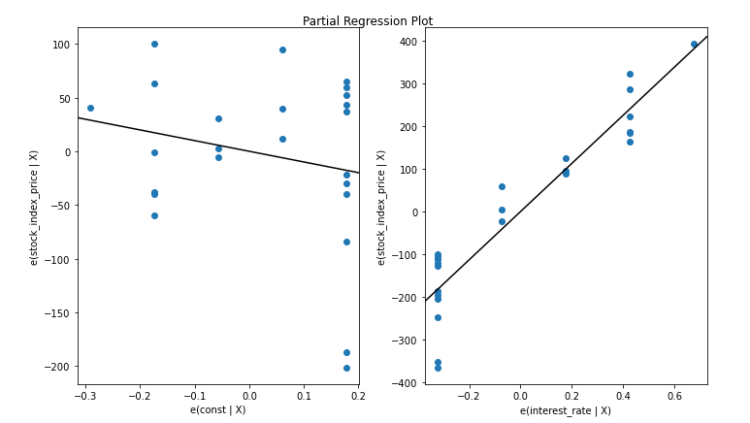
Now, let’s do a regression plot of the fit of the model. The fit is of average quality.
fig = plt.figure(figsize=(10, 6)) fig = sm.graphics.plot_partregress_grid(model, fig = fig)
And now here is the code in R.
First, we import the necessary libraries.
library("rjson") library("tidyverse") library("dplyr")
Now we will load the data which is in json format.
result <- fromJSON(file = "data.json")
Let X be the independent variable, and let Y be the dependent variable. We will load the third column of our data which is the interest rate into X, and the 5th column into Y which is the stock index price.
X <- result[c(3)] Y <- result[c(5)]
The lm() function will fit a linear model to relations and the unlist() function converts lists to vectors.
relation <- lm( unlist(Y)~ unlist(X))
Now make a dataframe using the independent variable and use the relation found above to predict the stock index price
a <- data.frame(x = X) result <- predict(relation,a) print(result)
Let’s make a regression plot.
plot(unlist(X),unlist(Y),col = "blue",main = "Interest Rate & Stock Index Price", abline(lm(unlist(Y)~unlist(X))),xlab = "Interest Rate",ylab = "Stock Price Index")
Here are the model results:
We get results similar to our python model above and similarly, we’ll be looking at R-squared, Prob (F-statistic), and p-values.
-
- R-squared gives a general estimation of the quality of the fit and has a value between 0 and 1 (the higher the better).
-
- Prob (F-statistic) is a significance test for our model. If the p-value is less than 0.05, then it is usually taken as the model being significant.
-
- The coefficient p-values, and the direction of the effect.
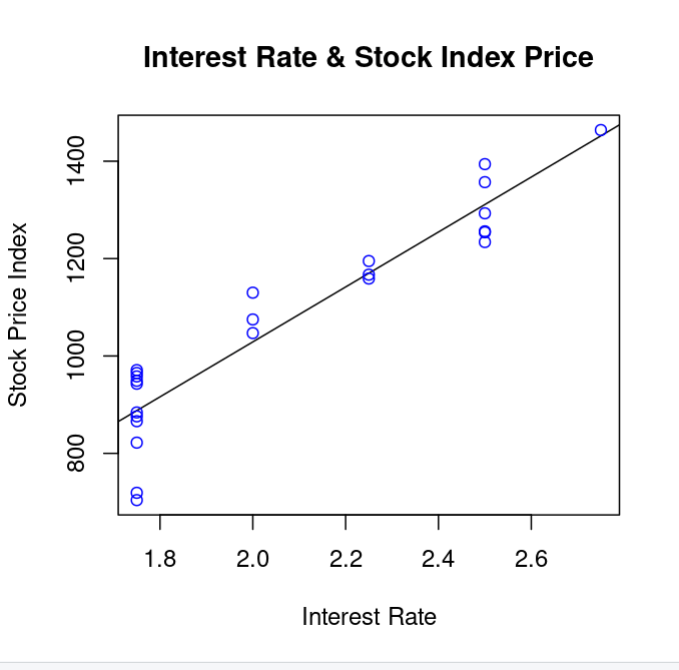
Here is the final regression plot.

Summary
In our article, we discussed some of the basic concepts of data analytics that would help any aspiring data scientist who is starting their journey in this domain. We discussed different types of analyses and the different types of tools being used. Then we saw how Python and R can be used to conduct data analysis.
If you’re an aspiring data scientist trying to enter the domain of data analytics or a skilled professional trying to acquire new skills, you can reach out to us or continue reading our other blogs. Also, make sure to check Beyond Machine which helps you become a data scientist and get a job in the field, no matter your prior knowledge.