Supervised PCA is a very useful, but under-utilised, model.There are many cases in machine learning where we deal with a large number of features. There are many ways to deal with this problem.
If we suspect that many of these features are useless, then we can apply feature selection techniques such as:
- Univariate methods: Chi-square test, or rank by using information-based metrics (e.g. mutual information).
- Recursive feature elimination.
- Embedded feature selection: L1-regularization (e.g. LASSO), or random forests.
All these methods make various assumptions. An assumption that is not very common is that the features are clustered in a way so that the features within a cluster are highly correlated.
However, there are cases where this assumption is actually quite realistic. For example, this is the case for genomics. The number of input features is large and many genes are correlated with each other.
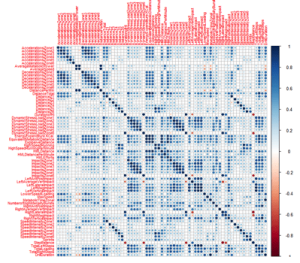
Another similar case is wearable technologies. For example, there are many sports clubs that are using GPS wearables. During my research I had the opportunity to work with STATSports Viper. Viper produces tons of variables for each session, most of which are correlated with each other. For example, accelerations, decelerations and the total number of sprints. In the figure below you can see the correlations amongst the different GPS features that were used in my research entitled “A supervised PCA logistic regression model for predicting fatigue-related injuries using training GPS data” (link opens to the Mathsports 2015 conference proceedings). Deeper blue means more highly correlated. It is easy to see that there are different groups of highly correlated variables.

Supervised PCA is a particularly good technique to attack these kinds of problems. Supervised PCA builds principal components with regards to a target variable. The original paper is by Bair et al. (2006) and you can also find it from Stanford.
Not only this algorithm can perform rather well in cases where this assumption is met, but it can replace a vast amount of features with a small number of components, correlated with the target variable. This can be extremely useful in contexts where interpretation is important.
In above aforementioned research I managed to reduce the total number of features from 70 to 3 components that directly correlate to football injury. Obviously, there are many other uses of Supervised PCA with a google scholar search showing around 75000 results.

If you want to run Supervised PCA yourself I would highly recommend the package ‘superpc‘ for R, created Bair and Tibshirani. The package supports regression and survival analysis. I have created another package called logisticSPCA which extends supervised PCA to classification through the use of logistic regression. The package also gives you the ability to use other generalized linear models, such as Poisson regression.
I have also created a Python version of the package that can work alongside scikit-learn.
Do you want to become data scientist?

Do you want to become a data scientist and pursue a lucrative career with a high salary, working from anywhere in the world? I have developed a unique course based on my 10+ years of teaching experience in this area. The course offers the following:
- Learn all the basics of data science (value $10k+)
- Get premium mentoring (value at $1k/hour)
- We apply to jobs for you and we help you land a job, by preparing you for interviews (value at $50k+ per year)
- We provide a satisfaction guarantee!
If you want to learn more book a call with my team now or get in touch.
References:
Bair, Eric, et al. “Prediction by supervised principal components.” Journal of the American Statistical Association 101.473 (2006).
Stylianos Kampakis, Ioannis Kosmidis, Wayne Diesel, Ed Leng (2015), A supervised PCA logistic regression model for predicting fatigue-related injuries using training GPS data, Mathsports International 2015