
Introduction
Natural Language Processing (aka NLP) is a branch of Artificial Intelligence that gives robots the ability to comprehend and derive meaning from human languages.
NLP combines computer science and linguistics to break down significant details from a human speech/text. Thus, AI tools like paraphrasers can mimic human-like speech in their results.
In this post, we will discuss how the latest NLP algorithms have helped elevate the functionalities of AI paraphrasers.
So, without any further ado, let’s get started.
Elevation of AI Paraphrasing Tools through NLP Techniques
Below we are going to discuss the common NLP algorithms/techniques used for enhancing the paraphrasing abilities of AI tools.
- Recurrent Neural Networks (RNNs)
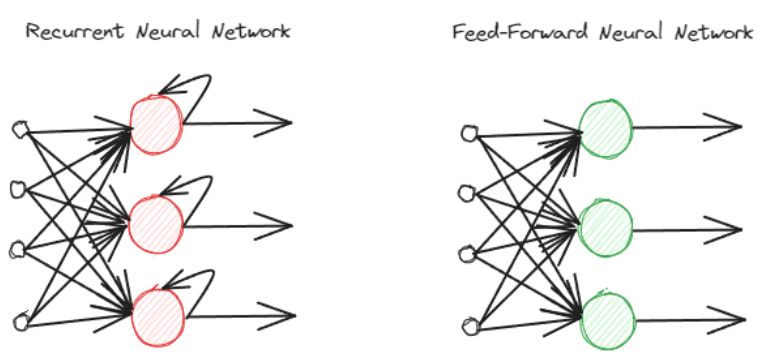
Source: KDNuggets
Recurrent Neural Network (RNN) is a type of artificial neural network that works by “remembering” the previous inputs to consider the next outputs. Meaning, that when used for reading a paragraph, the RNNs can recognize each word’s position in a sentence.
Implementation of RNNs is crucial to paraphrasing tools. It helps them successfully change sentence structures by correctly identifying the topic of a paragraph and the subject of each sentence.
Today, advanced RNNs have more hidden layers in their network. This has significantly improved the quality of paraphrasing tools as the output to the user comes through a longer chain of checks at the backend.
The increased hidden layers also help the AI tools to better understand different writing styles and tones. The recursive nature of RNNs has significantly enhanced the functionalities of AI paraphrasing tools. It allows them to refer to the history of inputs, which makes the paraphrasing tools come up with tonal-consistent answers.
The two most commonly used types of RNNs for NLP are:
- LSTM
LSTM stands for Long Short-Term Memory. It is a popular RNN architecture that was first introduced by Sepp and Juergen in 1997. LSTM has a better “memory” than other types of RNNs. Here are the reasons why LSTM is an advanced form of RNN used as an NLP algorithm:
- They work on predictive models consistently performing more iterations for each node’s input and output
- They consider past inputs AND possible future outputs to generate a decisive answer
LSTMs solve a long-lasting problem with RNNs. Typically, general RNNs would forget the placement of words or their meaning in context if they weren’t written in a single sentence.
For instance, if there is a sentence “James was struggling to keep up with his work due to his appendicitis.” Then, we know from this sentence that James has a disease holding him back from completing his tasks.
But if appendicitis was mentioned before this sentence or if it was mentioned implicitly. Then, the general RNNs would have never been able to connect that information and would completely misjudge the given context. This would lead to unreliable paraphrasing results from the AI tools.
However, LSTM-based NLP algorithms can potentially remember everything they read in a document. They will remember each word’s placement, its context, and the writer’s style/tone when saying it.
This is because LSTMs have “cells” in their hidden layers that control the information flow very nicely. Thus, they are highly useful in removing redundancy from texts and can help AI paraphrasers stay concise and accurate in their answers.
- GRU
GRU stands for gated recurrent units. Their core functionality as iterative neural networks is quite the same as LSTMs. However, they differ in other ways:
| LSTMs | GRUs |
| 3 logical gates: input, output, and forget | 2 logical gates: reset and update |
| Uses cell state to regulate the flow of information | Uses ‘hidden state’ to regulate information |
| Difficult to train due to their complex working nature | Easier to train and learn as they only have two gates |
| Very strong to remember long-term dependencies | Might suffer from long-term dependencies |
The workflow of GRUs is very different than LSTMs. They are like the simplified version of LSTMs as they only have 2 gates. Thus, they are easier to handle and train than LSTMs.
The update gate in a GRU retains information for a node. While the reset gate forgets some previously read information for the sake of coherence in the output.
However, each pro has its cons. The LSTMs are difficult to implement as NLP algorithms as they require a lot of computational power. But, they are more robust in their functionality and provide more accurate results. Hence, the decision to use the type of RNN depends upon the scale and purpose of your project.
- Word Embedding
Word embedding is a newly implemented technique in NLP. It works by breaking down each word into vectors, which is the numerical representation of words.
The vectors are numbers containing a particular word’s information like its context, definition, and semantic relationship with the other words. The vector representation helps the machine learn and predict similar words in the context. This is helpful for AI tools like paraphrasers to give synonyms of words according to their implied meaning in the text.
Let us take an example of a paraphraser tool to aid our understanding:
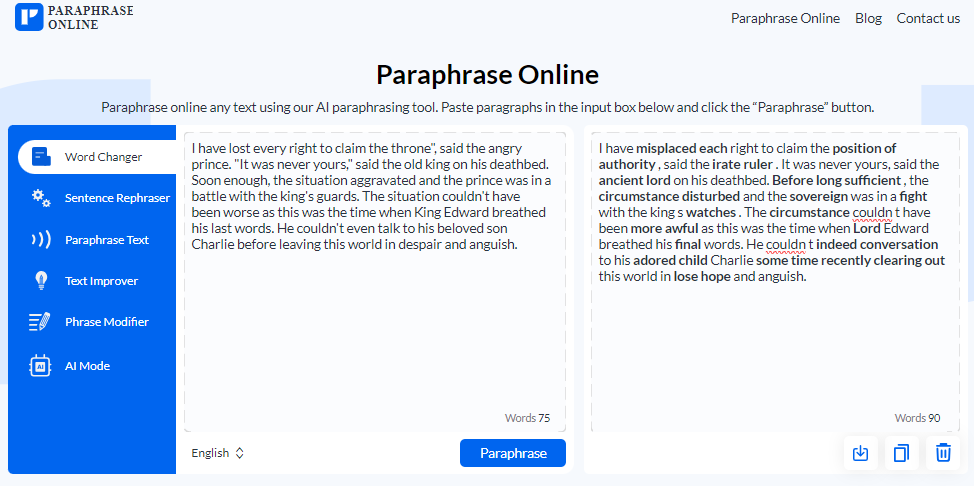
Here, the bold words represent the synonymized words in the context. This results in a successful paraphrase of the content without losing its tone or meaning.
Let us see the two most commonly used Word Embedding in the world of NLP algorithms.
- Word2Vec
As the name implies, the Word2Vec converts each word into a vector. It gives them weights regarding how accurate they think each word is in the context. So, even if the word they chose was inaccurate to the applied scenario (according to us), the model comes up with multiple options for the user to choose from.
Word2Vec operates on corpuses or search windows on a text. Meaning, that the person supervising the algorithm will provide it with a contextual word. The algorithm will determine/predict other words around it to successfully be able to reproduce a text.
Wait! There is a catch! A bigger size of the corpus for the Word2Vec algorithm will make it easier to process a document. However, it will lack small semantic (contextual) details between the clauses/phrases, making the generated text low in cohesion and coherence.
So, it all comes down to finding the suitable corpus size according to your project’s needs and scale.
- GloVe
GloVe stands for “Global Vectors for Word Representation.” It is another popular word embedding technique that is employed in NLP. It works in quite a similar way to making vectors of words. However, the key difference here from Word2Vec is that the corpus in GloVe is global. This means that it doesn’t need a corpus size to be defined. It analyzes the whole document as a whole and automatically establishes which word goes where.
Both GloVe and Word2Vec have been found to produce similar results. However, the key advantage that GloVe can have over Word2Vec is its ability to function unsupervised.
This means that, unlike Word2Vec, GloVe does not require any human intervention to work efficiently. Just provide it with the required textual document to index, and it will take care of the rest.
Limitations and Challenges with NLP Techniques
The NLP techniques and algorithms have advanced a lot. However, they still face many challenges in successful text comprehension and generation. Below we have listed some of them:
- Multiple meanings: Human languages are complex. The references and writing styles of text can vary significantly from culture to culture and region to region. The algorithms can sometimes misunderstand a context as words and phrases can have multiple meanings.
This is especially true in cases of idiomatic/sarcastic styles of expression. It gets tough to make the NLP algorithms learn accurate human emotive language.
- Incomplete data: If the words in a sentence are incomplete in any way, then the NLP algorithms will have a hard time deciphering them. And even if they do, there will be a high chance of wrong word classification and/or extraction.
- Quality of data: NLP techniques for creating effective paraphrasing AI tools require a lot of data for training the algorithm. The quality of data should also be high.
Meaning that the data should be from a wide range of domains and written without any grammatical errors or problems. Finding such rich data so frequently can be a huge challenge in implementing NLP techniques for AI tool development.
- Ethical concerns: NLP algorithms are processing large chunks of data (big data) which can raise some ethical and privacy concerns. There might be legal battles over the process of data collection, and/or misuse of sensitive information of people.
Final Thoughts
NLP techniques have advanced quite a lot in recent years. Their improved algorithms have allowed the AI tools like paraphrasers to work more efficiently.
The AI tools can now accurately change sentence structures and synonymize perfectly according to the context. However, there is still a lot of work to be done with NLP techniques.
That’s it for the post! We hope you enjoyed our content!