In an information-saturated world, many companies learn to benefit from the gigantic amount of data around us. Data is everywhere: millions of posts and breaking news are published and shared every single day. Internet users visit thousands of websites and make millions of purchases, leaving their digital footprint behind. Stock markets fluctuate, and the behavior of investors changes. It’s not a surprise that companies try to use this information to address their customers in a better way, make more informed business decisions, and predict changes.
While big data solutions often require considerable investments, decision-makers are still excited to take advantage of the opportunities they offer. Let’s take a look at statistics first.
Statistics and Market Overview
Big data analytics market is maintaining steady growth in recent years. Cloud computing plays a leading role in this big data transformation.
Many industries apart from information technology are processing data to improve workflows and gain competitive advantage. Healthcare, finance, agriculture, professional services, and many other industries implement big data solutions. The transformation is happening across all industries, and even small businesses nowadays often subscribe to AI products to gain access to professional data analytics.
In order to cut costs, developers use other platforms or ready big data infrastructure. Almost all big data solutions use ready platforms for data lakes as well as the data processing tools created by industry giants like AWS, Microsoft, IBM, and others. In this article, we are talking about a data lake, a solution that allows us to cut costs significantly.
Definition of a Data Lake
A data lake is a repository used to store large amounts of data in its original format and process this data accordingly. A big part of this data is unstructured, which makes data lake a powerful and essential part of real-time big data solutions. A data lake has a complex architecture that requires the right approach not only to make it work but also to minimize costs.
In addition to its role as a versatile data repository, a data lake also serves as a centralized hub for efficient media storage, making it easier to manage and access multimedia assets alongside other valuable data.
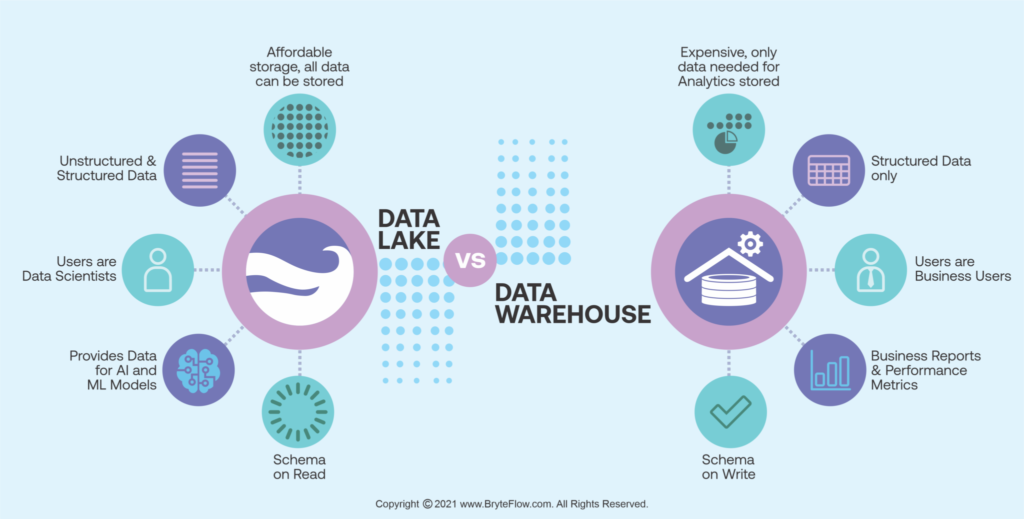
Data Lake vs Data Warehouse
In data analytics, there’s no set-in-stone terminology, so some people might even use these terms interchangeably. However, most of the community agrees that there is a certain list of features that defines a data lake. Let’s take a look at them and compare them with the same list for a data warehouse.
Data Lake
- Stores mostly unstructured data
- No preprocessing is required before storage
- Low-cost storage of huge amount of data
- Data is used for big data, AI, statistical analytics, predictions
Data Warehouse
- Stores structured data
- Data has to be processed before storage
- Storage is more expensive
- Data is used for reports, dashboards, business intelligence
The Architecture of a Data Lake
Essentially, there’s no set architecture for a data lake. Each data lake has its unique architecture consisting of tools, processes, and pipelines that power the data processing solution. This creates a powerful operating structure for processing big data.
However, we attempted to draw up the main aspects and processes of a typical data lake architecture. Usually, when architects model a data lake, they consider the following parameters:
Data ingestion
The data can arrive at a data lake from different sources and through different paths. There are typically two different data flows: real-time and batch. Real-time processing allows data scientists to train ML models and get data incredibly fast. Batch data processing is slower but more accurate than real-time processing. It has a latency of several hours and can be used for reports or dashboards.
Data storage
Developers need to consider which repository will store all the data. The data can be stored in a different form depending on its schema. Big data software developers usually have to buy cloud storage space provided by cloud service providers or use ready storage solutions provided by the industry giants like Apache, Snowflake, AWS, Azure, and others.
Data processing
Data lakes should have data processing tools that convert unstructured data into structured data. Then, this data can be used for analysis and gaining insights. Cleaning and categorizing data is also a part of data processing. Each data lake has several data processing pipelines depending on the data processing model (real-time or batch).
Data governance
Data Governance includes a whole philosophy on how a company uses data. Setting the right access management and implementing robust data security measures are the key steps. Then, it’s important to implement processes of data backup and disposal. Of course, the data governance policy should comply with the data regulations of your jurisdiction.
Conclusion
It looks like the world is moving towards better data management, and data lake is a key component in this journey. Data lakes are used as cost-effective and efficient repositories that can store different kinds of data. It’s an essential part of the architecture of big data solutions. Data lakes allow developers and stakeholders to work with huge volumes of data effectively.